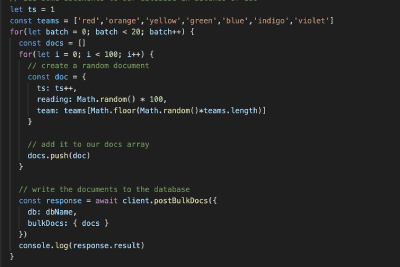


























How to recover a deleted document

How to recover a document in Cloudant that has been deleted or overwritten








Case-sensitivity in queries

Making Cloudant query, search and MapReduce case sensitive or case-insensitive
Improve and then improve some more

The journey our team took to move a modern CI using Jenkins Pipeline.



Fuzzy search using Double Metaphone

Using the Double Metaphone algorithm to find words that sound alike.









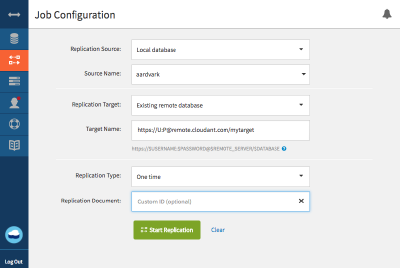
Partitioned Databases - Data Migration

Copying data from a standard database to a partitioned database.
Partitioned Databases - Data Design

Designing your data for a partitioned database, including indexing and querying