Understanding Indexing
While less convoluted than the read and write behaviour in a cluster, the behaviour of indexing in a clustered CouchDB or Cloudant environment merits a discussion. Understanding how indexing and querying works in a cluster will help avoid confusing situations where queries to a view index on Cloudant will produce different results because the indexes contain different data.
tl;dr: Writing indexing functions (map/reduce in views, index for search indexes and so on) which can return different values for the same input document will cause the indexes on shard replicas to differ, meaning they could return different values for the same query even when data doesn’t change. It’s the developer’s responsibility to write their indexing functions such that they always emit the same values for indexing for the same JSON input.
Single node querying🔗
First, a quick recap on how indexing and querying works on a non-clustered CouchDB instance. A single CouchDB node looks a bit like this internally:
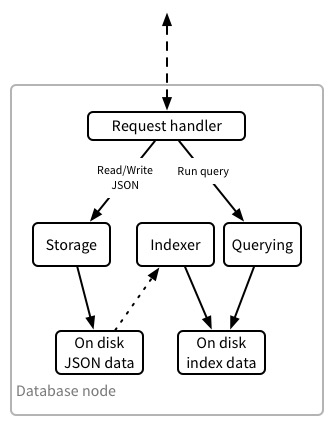
Writing works as follows:
- Request handler receives a write request. It forwards the request to the Storage engine.
- The Storage engine writes the JSON document into the on-disk file. Each write to the on-disk file increments a sequence value for the on-disk JSON data file.
- The Storage engine returns success or failure to the Request handler, which returns to the client.
A query is processed like this:
- Request handler receives a query. It forwards the request to the Querying engine.
- The Querying engine requests that the Indexer updates the on-disk index with the latest changes from the JSON data stored on-disk.
- The Indexer looks up the last sequence value it has for index being queried. The Storage engine uses this to give the Indexer a list of documents that have changed (new, updated or deleted) since that sequence value. The 4. Indexer takes this list of documents and updates the index with the changes. Of course, there may be no changes to process.
- When the index is up to date, the Querying engine looks up the result of the query in the index and returns it to the client via the Request handler.
For the purposes of this discussion, it’s fine to assume all the various index types CouchDB 2.0 and Cloudant support work the same way. In addition, we’ll put to one side the background index updating Cloudant does, and the various querying options which can change whether the index is updated in response to a query. These are irrelevant to the main points to be aware of when using CouchDB in a cluster or Cloudant.
Clustered querying🔗
Recall that in a cluster databases are divided into shards. Each shard is then stored three times across the cluster.
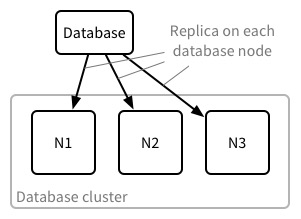
When considering indexing, it’s worth considering the cluster at two levels of abstraction. The first is the cluster layer: the code which makes the machines in the cluster appear as a single CouchDB instance. The second is thinking about indexing from the point of view of each node, more specifically:
- Each node N1, N2 and N3 is a standalone CouchDB instance.
- From the point of view of the lower-level code which implements indexing on N1, N2 and N3, each database shard replica is actually an independent CouchDB database sitting on that node’s disk. (It’s the clustering layer that handles knitting these databases into the larger, single, externally visible database).
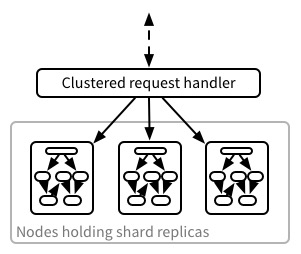
In a cluster, writing happens as follows (with the caveats from the this post):
- Write request arrives at the Clustered request handler.
- It works out which shard contains the document being written. It looks up which nodes host the replicas of the shard for the document.
- The Clustered request handler sends a request to each replica-hosting node asking it to write the document.
- Each node writes the document separately and responds to the Clustered request handler success or failure.
- Once the Clustered request handler receives n/2+1 responses (by default), it returns its response to the client.
There are a bunch of subtleties and failure modes in the above, but for now let’s pretend that writes always succeed.
The key point is that the nodes hosting the replicas write to their own component of the database independently.
Querying is similar:
- Query request for a given database arrives at the Clustered request handler.
- The Query request handler must ask every node that hosts a replica of a shard in the database for their answer to the query. Depending on how the shard replicas are distributed across the cluster, this might be all nodes in the cluster, or only a subset.
- Recall each node treats each shard as a database of itself. At this point the node proceeds as for the single database case, where its shard is the database: the node takes its shard replica, updates the index as above using the sequence value for its shard – each shard has its own sequence value because it’s a database – and returns the results for its shard. Each node could host replicas of multiple shards, so the node could be carrying out this process for several shards in parallel.
- The Clustered request handler takes the first response received from a node hosting each shard and knits the responses together into the aggregate response for the database as a whole.
Point (3) is the key one here. Each shard has its own index and each node updates the index for its replica of the shard independently of the other nodes. This means that if the values a node calculates to store in the index are different to other nodes, the indexes stored on each node will be different. In that event, each replica may return different results for a given query even if the data does not change. Scary.
Avoiding inconsistent queries🔗
The good news is that its simple to avoid this situation. It just requires that the developer writing indexing functions follow a single rule: never use information aside from the values passed to the indexing function – usually the JSON document, but it could also be the inputs to a reduce function – to calculate values for the index.
To understand the rule, first consider the question: how can a replica end up with a different value in its index to those of the other replicas of a shard? It’s down to the way CouchDB handles calculating index values: the developer provides (typically) a JavaScript function which processes a document and outputs the values to be indexed for that document. If the developer doesn’t take care to ensure that the function always returns the same index values for a given document, different replicas may end up with different values in their indexes.
The most common example is using the current date during indexing. For example the following map function is almost certain to cause problems:
function map(doc) {
emit(Date.now(), doc);
}
Each replica will run this function at a different time, and so the emitted key will be different on every node. Often the emitted values will only be a millisecond or two different, but it could be much more. Imagine a node in the cluster needs to be replaced. One option to do that is to comission a new node and replicate the data to that node. The new node will index the data as it receives it – which could be days, months or even years after the other nodes indexed each document!
So remember the key rule when writing your indexing function: never use any information that’s not contained in the input passed to the function.
As a side note, Cloudant Query/Mango uses a declarative syntax to declare indexes and so doesn’t leave open the possibility of introducing inconsistent indexes in this manner.
Why indexing works the way it does🔗
On the surface, another way to avoid inconsistency in replica indexes would be to only calculate the values to index on one node, and then send that value to the other replicas.
This approach wouldn’t work in practice, however, if we want to maintain availability. To do things this way, there would need to be some concept of a primary node which is in charge of generating indexed values. In the face of a network partition, nodes on one half of the partition wouldn’t have access to the primary indexing node, so would be unable to update their indexes, effectively making querying unavailable on that side of the partition.
As availability is a primary goal of CouchDB’s clustering, indexing necessarily must happen independently on each node. To do this successfully does require some care as a developer using CouchDB. However, the flexibility of custom indexing functions combined with CouchDB’s availability often makes this care worth taking.