Analysing Backups with SQL Query
Note: Given the age of this blog post, several links may be broken.
In this post we discussed storing time-series data in time-boxed Cloudant databases to allow recent data to be stored in Cloudant and older data to be archived and deleted from Cloudant. In this post we’ll examine how to query data that has been archived and backed up to Object Storage using the IBM SQL Query service.
Object storage is much cheaper per gigabyte than a database, is endlessly extensible and makes a great choice for storing backups and archived data.

Photo by Federico Bottos on Unsplash
Pre-requisites🔗
- An IBM Cloud account.
- An IBM Cloudant database service provisioned within your IBM Cloud account. Make a note of the URL of your Cloudant service - we’ll need that later. Make sure you have a database created in your Cloudant service containing
- An IBM Cloud Object Storage service provisioned within your IBM Cloud account. Create a bucket within this service making a note of the region and bucket name you have chosen.
- An IBM Cloud SQL Query service provisioned within your IBM Cloud account.
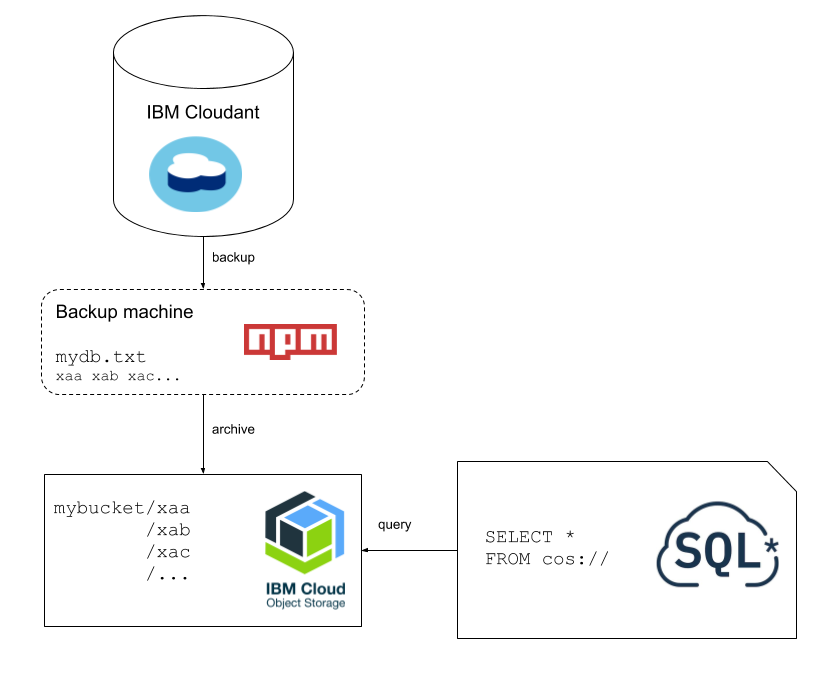
Getting the Cloudant data onto Object Storage🔗
We’ll be using the official couchbackup tool to extract data from Cloudant. It is a Node.js application and is therefore installed using the npm command-line utility:
npm install -g @cloudant/couchbackup
We can then store our Cloudant URL as an environment variable:
export COUCH_URL="<your Cloudant URL goes here>"
Assuming we’re backing up a database called mydb we would invoke couchbackup like so:
# make a shallow backup of the database
couchbackup --db mydb --mode shallow > mydb.txt
This creates a file called mydb.txt. Each line of that file is an array of JSON documents - one per document in the database:
[{"_id":"1"...},{"_id":"2"...},{"_id":"1"...},....]
[{"_id":"101"...},{"_id":"102"...},{"_id":"103"...},....]
[{"_id":"201"...},{"_id":"202"...},{"_id":"203"...},....]
...
Our first job is to remove the Design Documents from this file. The IBM SQL Query service is looking for flat JSON documents - those with top-level key values and not embedded objects. We can use the jq tool to filter out documents whose _id field starts with _design:
# remove design documents from the backup file
cat mydb.txt | jq -c 'map(select(._id | startswith("_design") | not))' > mydb2.txt
The above jq command is fed the file containing multiple arrays of objects. For each array, it iterates through each document and excludes those that are design documents. The output is fed to a second text file: mydb2.txt.
The final step is to extract each line of the file (each array of documents) to its own file. This is easily achieved with the split command-line tool:
# split each line of mydb2.txt into its own file
split -l 1 mydb2.txt
# remove the original files
rm mydb.txt mydb2.txt
We should now have a number of files (xaa, xab, xac etc) which can be bulk uploaded into a Cloud Object Storage bucket, in this case into a bucket called mydb.
Explore the data🔗
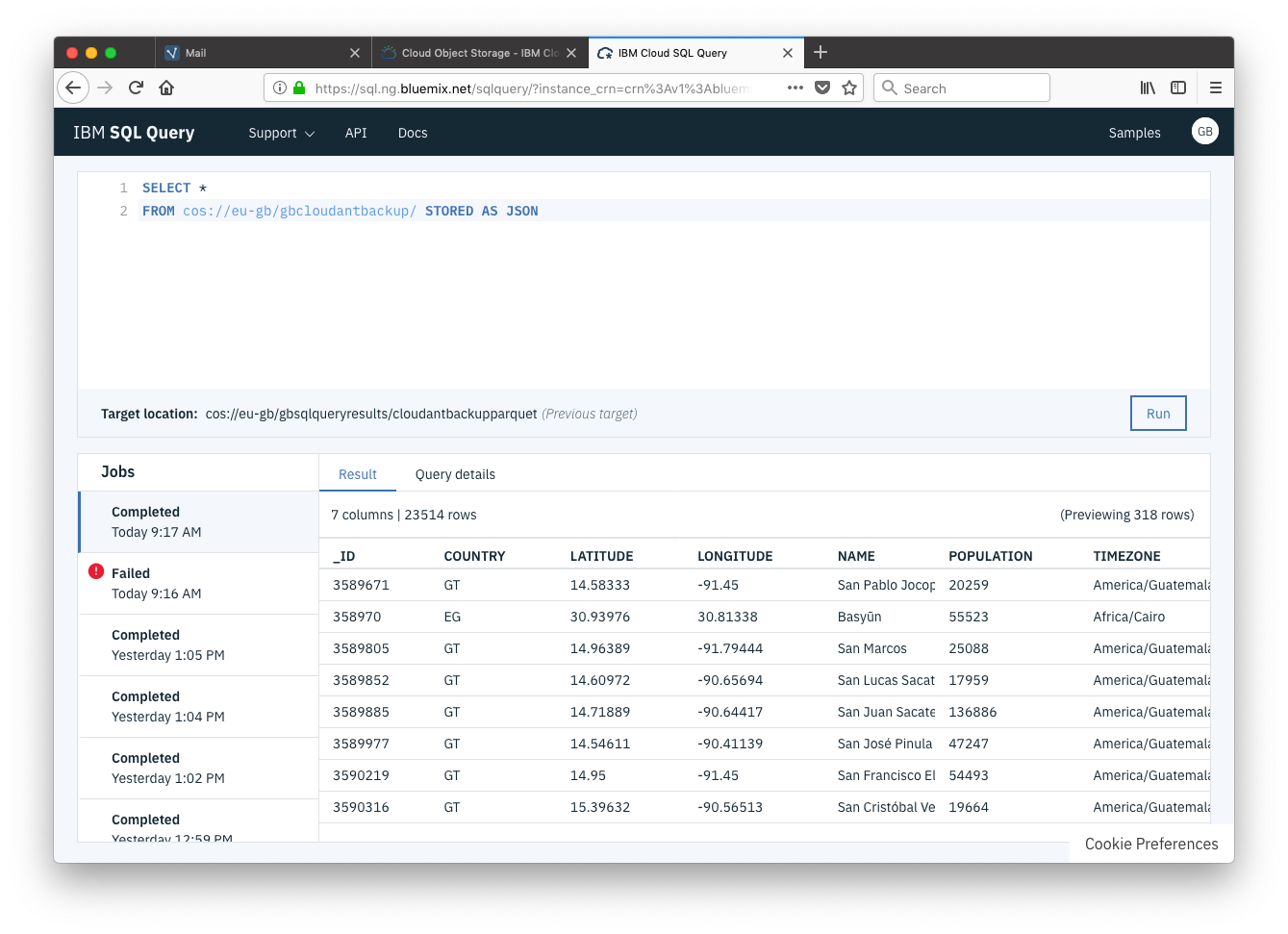
Now we have our JSON files in Cloud Object Storage, accessing them from IBM Cloud SQL Query is q breeze. We can access the data as if it were a SQL database:
-- explore the data
SELECT *
FROM cos://eu-gb/mydb/ STORED AS JSON
SELECT *- choose all columns.FROM cos://eu-gb/mydb/- from Cloud Object storage, in theeu-gbgeography from themydbbucket.STORED AS JSON- defines the file format of the stored data.
The output data is previewed in a table in the web page which is helpful for exploring the data; looking at the data’s column headings and data types.
Converting to Parquet🔗
Before we do any serious data exploration, it’s useful to do one last data conversion: to convert the JSON data into “Parquet” format. Parquet is a compressed, column-oriented format that comes from the Hadoop project. Data in this format is ideal for ad-hoc querying as it has a smaller data size and faster query performance.
Converting data to Parquet is a one-off operation that can be performed by executing a single Cloud SQL Query statement:
-- convert all data in 'mydb' bucket into Parquet format
-- to be stored in the 'mydbparquet' bucket
SELECT *
FROM cos://eu-gb/mydb/ STORED AS JSON
INTO cos://eu-gb/mydbparquet/ STORED AS PARQUET
In this case, I’m keeping my raw JSON data and the derived Parquet files in different Cloud Object storage buckets for neatness.
The result of this operation isn’t a table of data in the UI, it simply writes its results to the destination bucket. Exploring the bucket in the Cloud Object Storage UI reveals the resultant objects:
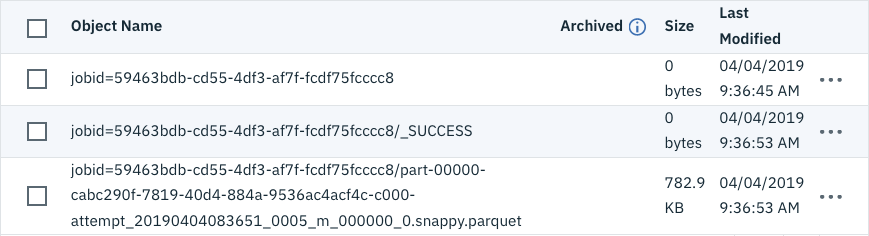
Notice that my 3.2MB of data is now only occupying 782KB of space as a Parquet file.
We can now direct queries towards the Parquet version of our data:
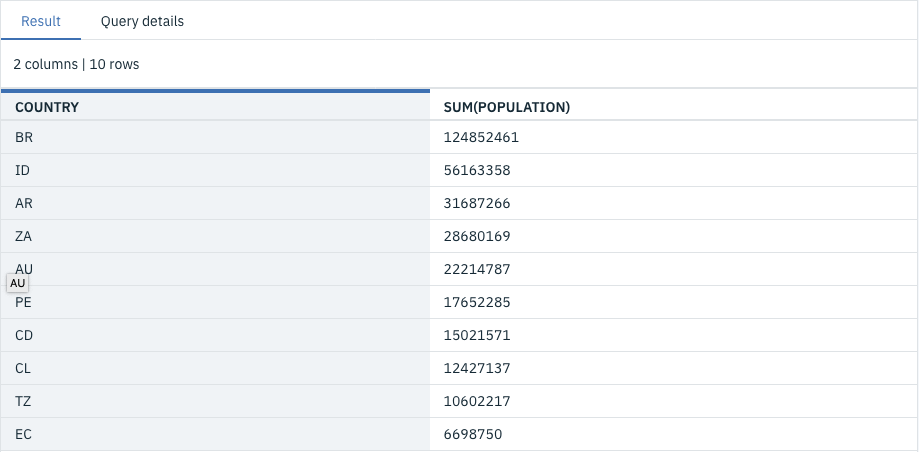
-- get top 10 populated countries below the equator
SELECT country, SUM(population)
FROM cos://eu-gb/mydbparquet/jobid=59463bdb-cd55-4df3-af7f-fcdf75fcccc8 STORED AS PARQUET
WHERE latitude < 0
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10
Doing more with Cloud SQL Query🔗
Once you’ve got the hang of exporting Cloudant data to Object storage, converting it to Parquet and analyzing it with Cloud SQL Query, the whole operation can be scripted to run automatically. Your timeboxed Cloudant data can be archived periodically and added to your data lake for analysis.
Cloud SQL Query can do much more than outlined in this article: check out its SQL Reference, Geospatial toolkit and Timeseries functions.