The Data Warehouse
Addendum: Since publication of this blog, couchwarehouse has added support for MySQL and PostgreSQL as well as SQLite. This post is still valid, but bear in mind you now have a choice of target database types.
One of Cloudant’s best use-cases is as a rock-solid, always-on operational datastore. It is built for fault-tolerance, storing multiple copies of your data on separate servers so that a Cloudant cluster can withstand the loss of multiple nodes without loss of service.
Let’s take the example of an online shop that uses Cloudant to store its transactions. At the birth of the business its sales database is empty, but as time progresses and as the business becomes more successful, the database grows to a healthy size - perhaps hundreds of thousands or millions or documents. The management of the company will be asking questions of the database:
- How many sales did we make this week?
- What are the top ten products sold?
- What are the peak times for selling a particular type of product?
- How successful was our “Halloween” marketing campaign?
Although Cloudant has built-in MapReduce which can provide simple aggregations of data against pre-defined keys (e.g. sales by year/month/day), it will eventually fall short of a business analyst’s expectations when faced with complex, ever changing queries or questions that relate the sales data to other data sets (such as marketing click-through data).
If you need to ask ad-hoc questions of your data without affecting the performance of your operational dataset, then you need a Data Warehouse.
Cloudant is your high-uptime operational data store, and a Data Warehouse is a query engine, which organises its data in a way that optimises for querying rather than uptime or data resilience. If you need to ensure that critical data is stored in multiple locations with a high availability (and a handful of fixed queries) you need Cloudant. If you need to run an ever-changing set of complex queries you also need a Data Warehouse.

Photo by Samuel Zeller on Unsplash
The most common scenario is you need both, with Cloudant data being fed to a data warehouse periodically. In this post we’ll look at how we would write some code to copy and transform Cloudant data before writing it to relational database, allowing us to query using Structured Query Language (SQL).
What do the Cloudant documents look like?🔗
In our example, we are storing one document per completed sale:
{
_id: "001fgS954GN35e4NJPyK1W9aiE44m2xD",
customerId: "001edS7k4gJxqY1aXpni3gHuOy0WusLe",
customerEmail: "bob@aol.com",
saleDate: "2018-09-15",
saleTime: "10:56:22",
paymentRef: "PayPal584477238823",
currency: "GBP",
basket: [
{
productId: "A6624",
productName: "Fender Road Worn 60's Jazzmaster",
productVariant: "3-tone burst"
},
{
productId: "B8852",
productName: "Fender '68 Custom Twin Reverb",
productVariant: null,
}
],
total: 2390,
status: "paid",
dispatched: false,
dispatchAddress: {
street: "19 Front Street",
town: "Middletown",
zip: "W1A 1AA"
},
dispatchCourierRef: ""
}
Things to note:
- This document contains everything we need to know about a sale. There may be further supplemental information about the user/product/payment in other databases, but fetching this document gives us enough information to render an “order summary” web page or email. This is good practice in a NoSQL database - in a database without joins, we don’t want to have to make several round-trips to the database to piece together all of the data we need.
- A document is created when the payment is confirmed.
- The document maybe updated later to indicate that the order has been dispatched and to back-fill the
dispatchCourierRef. - The document contains an array of products in the
basketfield which store one or more line items purchased.
How can I generate some sample data?🔗
Create a template.json file containing the outline of the document to create with placeholder tags where the data will be placed:
{% raw %}
{
"_id": "{{uuid}}",
"customerId": "{{uuid}}",
"customerEmail": "{{email}}",
"saleDate": "{{date 1999-01-01}}",
"saleTime": "{{time}}",
"paymentRef": "PayPal{{digits 16}}",
"currency": "{{currency}}",
"basket": [
{
"productId": "A{{digits 3}}",
"productName": "{{words 3}}",
"productVariant": "{{words 6}}"
},
{
"productId": "B{{digits 3}}",
"productName": "{{words 3}}",
"productVariant": "{{words 6}}"
}
],
"total": {{price 100 2600}},
"status": "paid",
"dispatched": {{boolean 95}},
"dispatchAddress": {
"street": "{{street}}",
"town": "{{town}}",
"zip": "{{postcode}}"
},
"dispatchCourierRef": ""
}
{% endraw %}
Then using the datamaker command-line tool, create thousands of sample documents and pipe them into the couchimport tool to write the documents to Cloudant:
$ datamaker -t ./template.json -f json -i 10000 | couchimport --db mydatabase --type jsonl
We can use a command of the above form to generate thousands, or millions of documents. Simply change the -i parameter to the number of documents you need.
How can I get Cloudant data into a Data Warehouse?🔗
A quick way of getting a queryable view of a Cloudant or CouchDB database is to use the couchwarehouse command-line tool. Once installed, creating a warehouse is simple from the command-line:
$ couchwarehouse --url https://U:P@host.cloudant.com --db mystore
The utility will attempt to discover the schema of your data, create a local SQLite database with a database table that matches your documents’ schema and begin populating the table from the Cloudant/CouchDB changes feed.
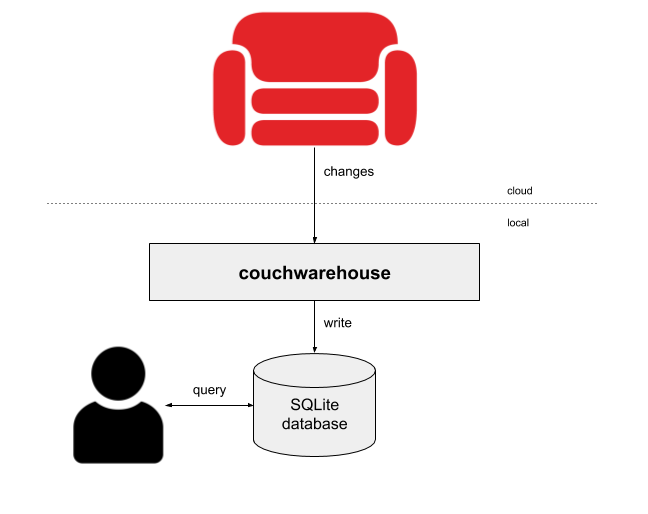
In another terminal, you can then run sqlite3 and begin querying your data with SQL:
$ sqlite3 couchwarehouse.sqlite
sqlite> SELECT customerEmail,dispatchAddress_town,status,total FROM mystore LIMIT 10;
customerEmail dispatchAddress_town status total
--------------------------------------------- -------------------- ---------- ----------
bettye-poirier@.gunma.jp Coseley paid 2553.02
myong-wilmoth@soliform.com Caernarfon paid 2492.27
tracibuckner@yahoo.com Pembroke Dock paid 824.66
moriah_beam@gmail.com Alnwick paid 939.03
aleciabernier@philobotanic.com Eccleshall paid 778.02
ashanti.purvis@samogonka.com Wakefield paid 1392.98
karima.bunn-gomez@redpoll.com Brynmawr paid 1214.42
guillermina-clarke@sialosyrinx.tuscany.it Kingston upon Thames paid 2408.66
mariah.houle@gmail.com Halesowen paid 269.92
holli.colley@yahoo.com Blackburn paid 144.65
sqlite>
Having the data in a SQL database database allows you to have complete flexibility in your queries. You can:
- Query sub-sets of data on any field.
- Create aggregations, grouped by any combination of fields.
- Join data to other data sets e.g. secondary “users”, “products”, or “postcodes” tables created in a similar way.
sqlite> SELECT dispatchAddress_town as town, SUM(total)
FROM mystore
GROUP BY 1
ORDER BY 2
DESC LIMIT 10;
town SUM(total)
---------- ----------
Newport 41067.81
Linlithgow 27923.21
North Berw 27328.37
Musselburg 24245.96
Dorchester 23587.35
Alton 22734.98
Swinton 22283.56
Westgate o 21819.46
Beaminster 21202.51
Audenshaw 20864.46
As long as the couchwarehouse utility is running, new and modified data will continue to spool into your local copy of the database. If you restart couchwarehouse again later, it will continue from where it left off and soon have your data warehouse up-to-date.
The couchwarehouse tool has a few other tricks up its sleeve
Transforming data before writing to the data warehouse🔗
You can optionally supply a JavaScript function using the --transform parameter which is used to transform each JSON document as it is consumed from the Cloudant changes feed. This is useful for type coercion, patching missing fields or enforcing default values.
Let’s say we want to simplify the basket array and turn it into a single string containing the product names. We would write a transformation function and write it to a file transform.js:
const f = (doc) => {
// if there's a basket array
if (doc.basket) {
// turn array of objects into array of product names
const nameList = doc.basket.map((v) => {
return v.productName
})
// join names by comma and overwrite the array
doc.basket = nameList.join(',')
}
// return the transformed document
return doc
}
// export the transformation function
module.exports = f
Running couchwarehouse with a transform function is simple:
$ couchwarehouse --db mystore --transform ./transform.js
Splitting multiple document types into their own databases🔗
Some Cloudant users store different document types in the same database e.g. customers, orders and products all together. Usually such documents have a “type” field which distinguishes each document’s type.
{
"_id": "123",
"type": "customer",
"name": "Bob Sessions",
"email": "bob.sessions100@aol.com",
"dob": "1924-02-05",
"pet": "dog"
}
{
"_id": "456",
"type": "product",
"name": "Fender Deluxe Reverb",
"supplier": "Fender Inc",
"rrp": 999.99
}
{
"_id": "789",
"type": "order",
"customerId": "123",
"customerEmail": "bob.sessions100@aol.com",
"saleDate": "2018-11-08",
"saleTime": "09:24:22",
"currency": "USD",
"basket": [ { "productId": "456", "name": "Fender Deluxe Reverb"} ],
"total": 999.99,
"status": "paid",
"dispatched": true,
"dispatchAddress": {
"street": "8442 Whitsbury",
"town": "Ivybridge",
"zip": "SP3 1TS"
}
}
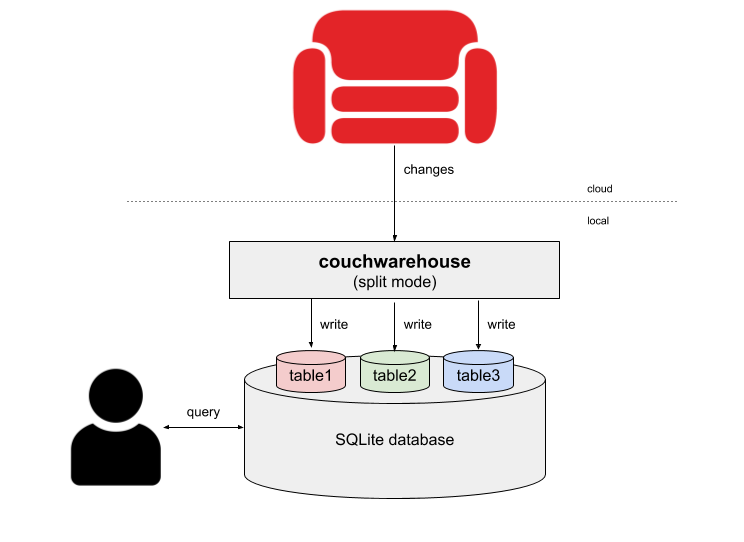
Supplying the name of the “type” field to the --split parameter instructs couchwarehouse to create multiple tables - one for each document type e.g.
$ couchwarehouse --db mystore --split type
This will create multiple tables in SQLite, one per document type:
mystore_usermystore_productmystore_order
What’s the catch?🔗
- This tool is only suitable if all of the documents in a database are uniform. Cloudant allows you to vary the schema over time, so you can have some documents with fields that others don’t. The couchwarehouse tool assumes the first document it sees is representative of the rest.
- Cloudant databases can get “big”. You need enough space on your local machine to store all of your data.
- The couchwarehouse tool doesn’t do anything special with embedded arrays. It stores the arrays as JSON text in the SQLite database, although the JSON text can be accessed at query-time using the SQLite JSON extension e.g.
SELECT json_extract(basket,'$[0].productId') FROM mystore. - The bodies of conflicted documents are ignored. Only “winning” revisions make it to the warehouse.
The couchwarehouse makes a fair guess at moving Cloudant data to a SQL database without any custom work. For anything more complicated, or to store data in a different database, you’re going to need some custom code.
How could I write my own data warehouse?🔗
Data Warehouses, such as IBM Db2 Warehouse on Cloud are based on traditional, table-based database engines. The data is arranged in tables with a fixed schema. To transfer data from Cloudant to a Data Warehouse we’re going to need to:
- normalise the data - store data in different tables with references to data in other tables via keys.
- create a schema which models all or part of the JSON object.
In this case I can see two tables being created:
sales- one row per completed salesales_basket- one row per item in the basket
The first table, sales, will have the following schema with one row per sale:
| field | type | cloudantPath |
|---|---|---|
| id | string | doc._id |
| customerEmail | string | doc.customerEmail |
| datetime | Date | doc.saleDate + ’ ’ + doc.SaleTime |
| paymentRef | string | doc.paymentRef |
| currency | string | doc.currency |
| total | float | doc.total |
| status | string | doc.status |
| dispatched | boolean | doc.dispatched |
| dispatchStreet | string | doc.address.street |
| dispatchTown | string | doc.address.town |
| dispatchZip | string | doc.address.zip |
| dispatchDate | date | doc.dispatchDate |
| dispatchCourierRef | string | doc.dispatchCourierRef |
The second table, sales_basket, with one row per line-item:
| field | type | cloudantPath |
|---|---|---|
| id | int | |
| salesId | string | doc._id |
| productId | string | doc.basket[].productId |
| name | string | doc.basket[].productName |
| variant | string | doc.basket[].productVariant |
The sales_basket.salesId field is a foreign key corresponding to the respective entry in the sales.id field. There is said to be a “one to many” relationship between sales and sales_basket. For each Cloudant document we’d have to make one write to the sales table and one or more writes to the sales_basket table (one per basket item).
After creating the target database tables manually to match the schema of your source data, we would need to write some software, similar to couchwarehouse, that spools data from Cloudant to the SQL database tables. The software would have to:
- Listen to the Cloudant changes feed from the source database.
- Transform the incoming documents into “INSERT INTO…” or “REPLACE INTO…” SQL statements that match the target tables.
- Transform date/time fields in Cloudant into native date/time fields in the database.
- Deal with changes that signify deleted documents (
deleted: truein the changes feed) would correspond to “DELETE FROM …” SQL queries in the table or joined tables. - Ignore design documents - documents whose
_idfield starts with_design/. - Keep track of the latest sequence token that Cloudant supplies with every change. When resuming the changes feed, Cloudant can be instructed to resume “since” your last known sequence token.
- Commit the INSERT/REPLACE/DELETE SQL statements to your database. Multiple writes that pertain to the same Cloudant document should be grouped into the same SQL “transaction”. For performance reasons, it is likely that you’d want to write multiple documents’ SQL statements together in bulk.
- Manage schema changes - although the documents’ schemas in Cloudant can evolve over time, your data warehouse schema (and custom code) would have to be modified to cope with any changes.
It’s pretty tricky to get this right. What happens with null or missing fields? Can your code handle receiving data of the wrong data type? Can your code handle processing the same change again or in a different order (the Cloudant changes feed may provide changes before your supplied sequence token and makes no guarantee on the order you receive the changes)?. Can your code keep a reliable replica of the Cloudant data including foreign key relationships across multiple tables?
If you can overcome this complexity and manage to get a copy of your Cloudant data in a data warehouse then you can use it to explore the data for analytics, data science and reporting purposes without affecting the load on your primary Cloudant database.
I don’t have a magic wand that can perform these actions - it’s going to require custom code written with your application in mind. By all means, use the couchwarehouse source code as inspiration, but it’s going to require some custom work nonetheless.