Searching Jekyll Sites
I’m a big fan of Jekyll for building static websites. If you’re not familiar with Jekyll, it takes a collection of configuration, templates and source files (I write my posts in Markdown) and transforms them into static HTML files that can be delivered to the world by any web server. Jekyll is built into GitHub Pages so that you can host the source files for your website or blog in a Git repository and have the resultant static web site served out by GitHub Pages without having to manage any server infrastructure yourself. As of May 2018, GitHub Pages now supports HTTPS on your custom domains.
Static sites are fast and easy to manage but without any dynamic server-side components, they may leave your users without features they expect, such as search. In a Wordpress-style blog, the content is served out from a MySQL database and site search is powered by querying that data set.

Photo by Clem Onojeghuo on Unsplash
On a static site, how can you allow your users to search the titles, tags and content of your blog if the data doesn’t reside in a database and there’s no server-side layer that can render dynamic pages? Here’s how it can be done:

- Create a static website with Jekyll and serve it out on GitHub Pages, or another static site hosting service.
- Write some code to poll the site’s Atom feed. A serverless platform like IBM Cloud Functions can be used to run the code periodically.
- Write the Atom Feed meta data into an IBM Cloudant database that has a free-text search index configured.
- Query the Cloudant database directly from the web page whenever a search is to be performed.
Let’s dive into the detail.
Building a blog with Jekyll🔗
There are plenty of guides that show you how to build a Jekyll-powered blog on GitHub Pages or follow the Jekyll documentation’s Quick Start Guide.
Once your blog is setup, make sure it has an Atom feed published at the /feed.xml endpoint. This is powered by the jekyll-feed plugin.
Schema design🔗
In order to add a search tool to your static blog we’re first going to need a database of blog post meta data. Using Cloudant as the database, we can store one JSON document per blog post like this:
{
"_id": "3d8d5d582576d35c984ba7b328190f72",
"_rev": "1-57b755340a3b760b5cef4f3018f0d9fb",
"title": "Cloudant replication with couchreplicate",
"description": "One of Apache CouchDB™’s killer features is replication...",
"date": "2018-02-22T09:00:00.000Z",
"link": "http://myblog.com/2018/02/22/Cloudant-Replication-with-couchreplicate.html",
"author": "Glynn Bird",
"image": "http://myblog.com/assets/img/replication-screenshot.png",
"tags": [
"Replication",
"CLI"
]
}
All of this data can be gleaned from the blog’s feed.xml Atom feed with two exceptions:
- the _id field needs to be unique - we can use a hash of the URL of the blog post.
- the _rev field is generated by the database and indicates the revision of the document.
First sign up for a Cloudant service and log into the dashboard. Create a new database called blog.
In that database we need to define a Cloudant Search index to answer free-text queries. Choose New Search Index from the menu next to “Design Documents”:
Then we can define an index by creating a JavaScript function that is executed for every document in the database, calling index for every value that is to be searchable:
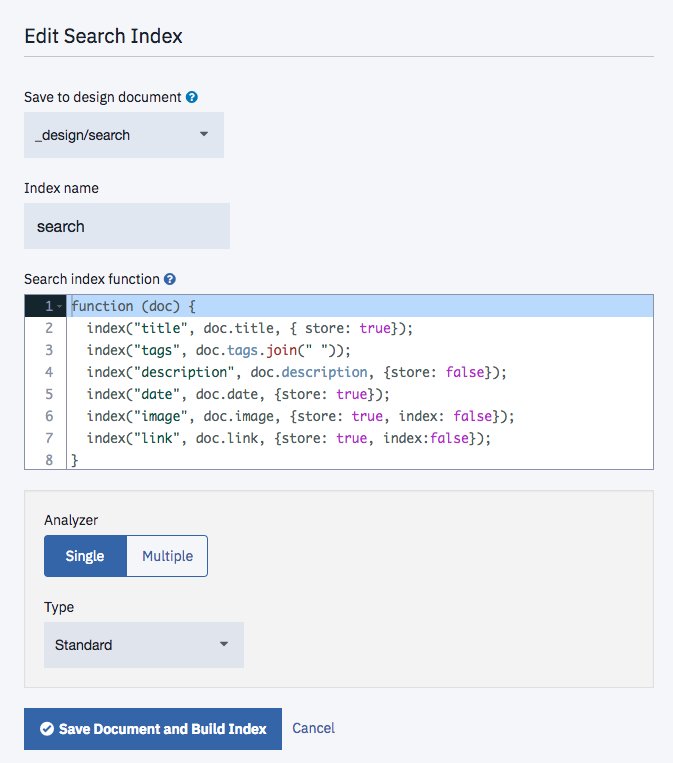
function (doc) {
index("title", doc.title, { store: true});
index("tags", doc.tags.join(" "));
index("description", doc.description, {store: false});
index("date", doc.date, {store: true});
index("image", doc.image, {store: true, index: false});
index("link", doc.link, {store: true, index:false});
}
The index function takes three parameters:
- The name of field to be stored in the index e.g.
"title". - The value to be indexed e.g.
doc.title. - An options object. When
storeis set to true, a copy of the value is stored unaltered in the index for retrieval at query-time. Whenindexis set tofalsethe value is not indexed for search, but is reproduced in the search results.
CORS and effect🔗
If we want to be able to query our Cloudant database directly from a web page, we need to make two further tweaks to the Cloudant configuration.
Firstly we must enable CORS (Cross-Origin Resource Sharing) in the Cloudant dashboard:
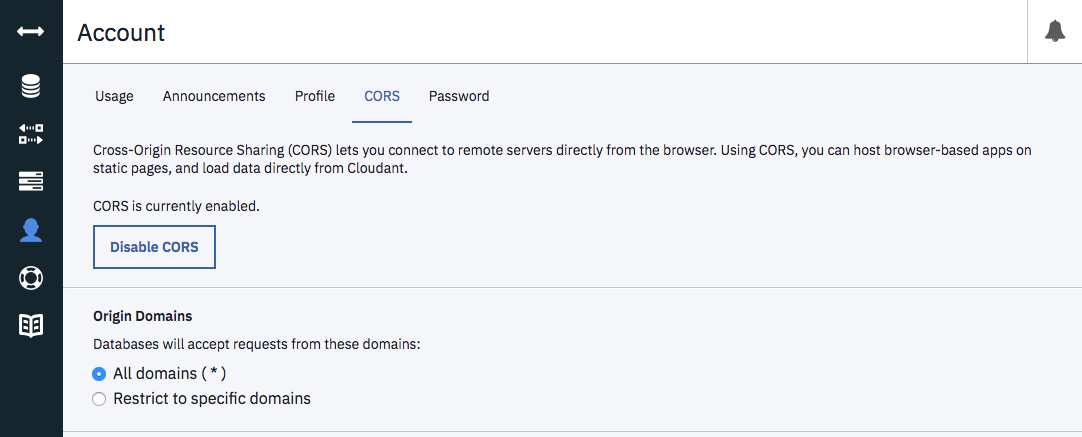
Enabling CORS instructs Cloudant to output the HTTP headers that will allow an in-page web request (sometimes called an AJAX request) to proceed without an error. By default, the rules-of-the-road for the web wouldn’t allow a web page to fetch JSON from a different domain name, and CORS is the work-around.
Secondly, we need to make the database readable. You can either make the database world readable (grant _reader access to everyone) or create an API Key that grants _reader access to our database of blog post meta data. Both options are accessible from the “Permissions” panel in the Cloudant dashboard:
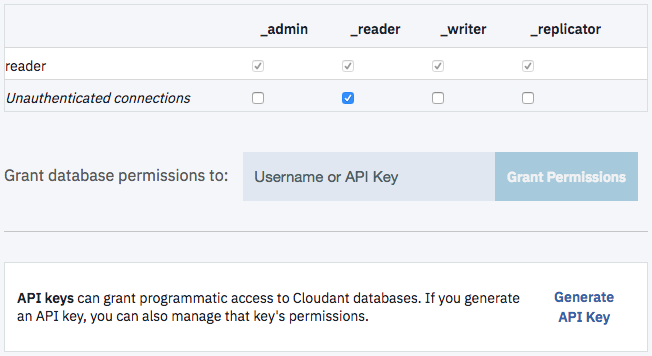
Now our database is created and set up, we need a script to poll the blog’s Atom feed, convert it to JSON and write it to the Cloudant database.
Atom feed poller🔗
We can write a simple Node.js script to fetch the Atom feed using a handful of npm modules:
- @cloudant/cloudant - to interface with the Cloudant database.
- request to fetch the Atom XML,
- feedparser to parse the Atom XML.
- striptags to remove HTML tags from the content.
The code itself then becomes pretty simple:
const FeedParser = require('feedparser')
const request = require('request')
const striptags = require('striptags')
const crypto = require('crypto')
const cloudant = require('@cloudant/cloudant')
// create an MD5 hash of the supplied string
const md5 = function(string) {
return crypto.createHash('md5').update(string).digest('hex')
}
// poll an RSS feed, return an array of items
const poll = function(url) {
return new Promise((resolve, reject) => {
var req = request(url)
var feedparser = new FeedParser()
var items = []
req.on('error', function (error) {
// handle any request errors
});
req.on('response', function (res) {
var stream = this; // `this` is `req`, which is a stream
if (res.statusCode !== 200) {
this.emit('error', new Error('Bad status code'))
} else {
stream.pipe(feedparser);
}
});
feedparser.on('error', function (error) {
reject(error)
});
feedparser.on('readable', function () {
// This is where the action is!
var stream = this // `this` is `feedparser`, which is a stream
var item = null
while (item = stream.read()) {
items.push(item)
}
});
feedparser.on('end', function() {
var newitems = []
for (var i in items) {
var item = items[i]
var newitem = {}
newitem._id = md5(item.link)
newitem.title = item.title
newitem.description = striptags(item.description)
newitem.date = item.date
newitem.link = item.link
newitem.author = item.author
newitem.image = item.image.url
newitem.tags = item.categories
newitems.push(newitem)
}
resolve(newitems)
})
});
}
const main = function(opts) {
return poll(opts.BLOGURL).then((items) => {
var db = cloudant({account: opts.ACCOUNT, password: opts.PASSWORD, plugins: ['promises']}).db.use(opts.DBNAME)
return db.bulk({docs: items})
})
}
exports.main = main
The main function is passed an object with the following attributes:
BLOGURL- the URL of the blog’s Atom feed.ACCOUNT- the admin username of the Cloudant service.PASSWORD- the admin password of the Cloudant service.DBNAME- the name of the Cloudant database to write to.
We can deploy this code to IBM Cloud Functions using the bx wsk tool (substituting your Cloudant account, password and blog URL):
# create a package called cloudantblog containing the config
bx wsk package update cloudantblog \
--param ACCOUNT "myaccount" \
--param PASSWORD "mypassword" \
--param DBNAME "blog" \
--param BLOGURL "http://myblog.com/feed.xml"
# add an action into the package
zip -r poll.zip index.js node_modules
bx wsk action update cloudantblog/poll --kind nodejs:8 poll.zip
# run periodically - every fifteen minutes
bx wsk trigger create cloudantblog_trigger --feed /whisk.system/alarms/alarm --param cron "*/15 * * * *"
bx wsk rule update cloudantblog_rule cloudantblog_trigger cloudantblog/poll
IBM Cloud Functions now has your polling code and is invoking it every 15 minutes. The script fetches your blog’s Atom feed turns it into JSON ready to be inserterd into the Cloudant database and then writes all the records in a single bulk request. It manages to deduplicate the listings because it uses a hash of the document’s URL as the document id - Cloudant won’t accept two documents with the same _id so duplicates are rejected.
Performing searches🔗
Our database should contain some documents. Let’s see them by querying our database’s _all_docs endpoint:
export COUCH_URL="https://USER:PASS@HOST.cloudant.com/blog"
curl "$COUCH_URL/_all_docs?include_docs=true"
# {"rows":[...])
You should see a handful of documents.
Now we can query the search index we created earlier:
curl "$COUCH_URL/_design/search/_search/search?q=*:*"
{
"total_rows": 10,
"bookmark": "",
"rows": [
{
"id": "4281157a51e3f0c16fea1596fa10713e",
"order": [
1,
0
],
"fields": {
"image": "http://localhost:4000/assets/img/kristina-tripkovic.jpg",
"date": "2018-04-27T08:00:00.000Z",
"link": "http://localhost:4000/2018/04/27/Cloudant-Fundamentals-1.html",
"title": "Cloudant Fundamentals 1/10"
}
}
...
]
}
The the q=*:* matches every indexed record. The array of rows returned contains a fields object containing each item indexed with store: true during the indexing process.
Imagine we wish to answer a user query for documents matching the search phrase “red apples”, then we can construct a Cloudant Search query to look for “red apples” in the description field:
description:'red apples'
A better search for this use-case is this:
title:'red apples'^100 OR tags:'red apples'^10 OR description:'red apples'
The above query matches the title, tags or description fields against the query string, but attaches greater weight to title matches, than tags or description matches. This use of the ^ operator weights the search results to bring more relevant documents to the top of the results.
We can send this query to Cloudant using curl:
curl "$COUCH_URL/_design/search/_search/search?q=title:'red+apples'^100+OR+tags:'red+apples'^10+OR+description:'red+apples'"
Querying from the front end🔗
The final piece of the puzzle is making the search request from inside a web page. Here there are myriad options:
Let’s use fetch because it’s new and shiny and it couldn’t be easier:
// search string looking for 'red apples' in title/tags/description
var url = "https://myhost.cloudant.com/blog/_design/search/_search/search?q=title:'red+apples'^100+OR+tags:'red+apples'^10+OR+description:'red+apples'"
// fetch the url
fetch(url).then((response) => {
return response.json()
}).then((json) => {
console.log(json)
})
// {"total_rows":10,"bookmark":"xxx","rows":[...]}
All that remains is to loop over the returned JSON’s rows attribute to pick out and render the data. How you do that depends on your front-end stack. I like the way Vue.js manages the plumbing between your JavaScript “model” and your HTML “view”. There are thousand other ways of building a dynamic page using other frameworks (React, Angular, Ember et al) or none:
// build search results HTML
var html = ''
for(var i in json.rows) {
const doc = json.rows[i].fields
html += `<p><a href="${doc.link}">${doc.title}</a></p>`
}
// update the web page
document.getElementById('content').innerHTML = html
Example🔗
The Cloudant blog is an example of this technology in action. It is a Jekyll-powered static website whose Atom feed is being polled by an IBM Cloud Functions action and whose search facility is powered by a Cloudant database containing the post’s meta data.