Cloudant Fundamentals 3/10
In part one of this series we looked at Cloudant JSON, and in part two we saw how an _id is made. In this part we’ll focus on the humble _rev token.
When you first create a document, you don’t need to worry about the _rev token — it is generated for you and returned to you in the receipt.
If we create a new document with a body of {"a":1,"b":2}, we get a reply from the database of:
{
"ok":true,
"id":"4245507c8acee2f2986298688244708c",
"rev":"1-25f9b97d75a648d1fcd23f0a73d2776e"
}
We can see the _id and the _rev if we fetch the document:
{
"_id":"4245507c8acee2f2986298688244708c",
"_rev":"1-25f9b97d75a648d1fcd23f0a73d2776e",
"a":1,
"b":2
}
Fields starting with the underscore character _ are reserved for Cloudant-specifc purposes. You can’t add your own custom _name field, for example.

Photo by Sergei Akulich on Unsplash
What is the _rev token?🔗
The _rev token consists of two parts separated by a hyphen character -:
- a number that increments with each version of the document
- a 32-character string that is a cryptographic hash of the document’s body.
Why does Cloudant have a _rev token?🔗
The _rev token keeps track of the revisions that a document goes through in its life:
- First revision 1-25f9b97d75a648d1fcd23f0a73d2776e
- Second revision 2-524e981baaeec9bbecf92c4c01242308
- Third revision 3-e95ca5ca4dc5407fd09b8e0e0acf25fd
Cloudant actually stores revisions in a tree data structure, the simplest form being an ever-growing list of revisions:
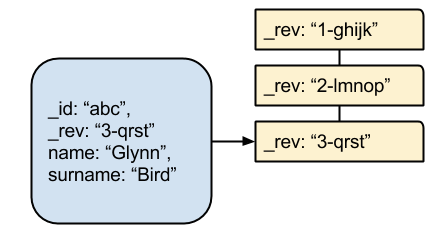
Things can get much more complicated than this when we talk about conflicts but that is for another time.
As to why data is stored like this, it’s because Cloudant was built to work as a distributed database with the data stored across many nodes in a cluster. Distributed systems are complicated, and the revision tree allows the database to handle conflicting writes without losing data, rather like Git would not lose data in a conflicting merge. The revision tree is also essential when replicating data from one location to another. Two databases in any state could be replicated in either direction without loss of data, thanks to the revision tree.
Can I use the revsion tree as a version control system for my documents?🔗
No.
Cloudant doesn’t keep the bodies of old revisions (they are destroyed in a process called “compaction”), but the history of revision tokens is retained.
Deleting a document creates another revision🔗
A Cloudant document can never really be deleted. When you do a delete API call another revision is added to the end of the tree:
- First revision 1-25f9b97d75a648d1fcd23f0a73d2776e
- Second revision 2-524e981baaeec9bbecf92c4c01242308
- Third revision 3-e95ca5ca4dc5407fd09b8e0e0acf25fd
- Fourth revision 4-d0b8f4e0375c952eb957de7dc1947aef
The last revision will look like this:
{
"_id", "4245507c8acee2f2986298688244708c",
"_rev":"4-d0b8f4e0375c952eb957de7dc1947aef",
"_deleted": true
}
Deleting a document leaves this final revision and the tree of revision tokens behind.
I don’t care about revision tokens - make them go away🔗
You can’t really make revision tokens go away, but there are libraries aimed at new starters that hide them from you so you can get on with building your app. Take a look at cloudant-quickstart which does just that.
Even if you are putting your fingers in your ears and pretending that revision tokens don’t exist, they are still being recorded in the database so you should try to avoid modifying the same document over and over if possible and be aware that a deleted document leaves a piece of data behind.
Next time🔗
In the next part we’ll take a look at using Cloudant’s HTTP API using the curl command-line tool.