The Revision Tree
On the surface, Cloudant’s document API appears to be a reasonably simple way to upload JSON data to a key value store and update the JSON data for a particular key. However, the reality is more complicated – isn’t it always? – and understanding what’s happening is important in using Cloudant effectively and becoming an advanced user of the database.
The takeaway point is this: a document in Cloudant is a tree and Cloudant’s document HTTP API is essentially a tree manipulation API.
Below, we’ll create and manipulate these trees to get a feel for what this means. The default behaviours of many calls allow you to ignore the tree in order that Cloudant appears more like a database, and we’ll explore why and how this works as we go.
Aside: why a tree? A document’s tree representation is key to Cloudant’s replication, which is essentially transferring tree nodes from one location to another in order to synchronise data robustly.
All this information is valid for CouchDB, but I’ve chosen to refer to Cloudant throughout for simplicity. This mini-tutorial assumes a basic knowledge of the Cloudant document API. Let’s get started.
Building a simple document tree🔗
Uploading a new document to Cloudant gives you something like this:
> curl -XPUT \
'http://localhost:5984/tree-demo/mydoc' \
-d '{"foo":"bar"}'
{"ok":true,"id":"mydoc","rev":"1-4c6114c65e295552ab1019e2b046b10e"}
Updating that document gives you this:
> curl -XPUT \
'http://localhost:5984/tree-demo/mydoc?rev=1-4c6114c65e295552ab1019e2b046b10e' \
-d '{"foo":"baz"}'
{"ok":true,"id":"mydoc","rev":"2-cfcd6781f13994bde69a1c3320bfdadb"}
Each call has returned a new rev ID in the response. If we didn’t already know the two rev IDs for this document, we could find them out by making a request for the document using the revs=true querystring parameter:
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc?revs=true' | jq .
{
"_id": "mydoc",
"_rev": "2-cfcd6781f13994bde69a1c3320bfdadb",
"foo": "baz",
"_revisions": {
"start": 2,
"ids": [
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
]
}
}
The special thing about this request is that the response lists the rev IDs in order – which defines the history of the document. From this call, we can construct a tree for the document with a single branch and two nodes. We use the _revisions field, and construct the tree backwards using the start and ids array:
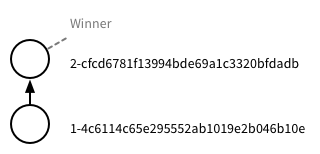
The tree has two nodes. Cloudant labels each node with its rev ID. Cloudant also labels one node winner; we’ll come to that in a moment.
Note: Cloudant calls these tree nodes revisions but I’m going to stick with node to emphasise the tree semantics.
Now we’ve seen the tree, let’s see how we can think about the three calls if we consider them in terms of trees rather updates to a JSON document.
- The first call creates a new document tree and its root node, 1-4c6114c65e295552ab1019e2b046b10e.
- The second call adds a node to the tree, parented by the node we pass in via the rev querystring parameter. The call returns the rev ID of the new node, 2-cfcd6781f13994bde69a1c3320bfdadb.
- The final call uses the revs=true parameter to return the history of the 2- node along with its content.
One other thing is worth mentioning at this point: a rev ID can be used to retrieve any node of the tree at any time. This is done by using the rev querystring parameter when making a GET request for the document. While that node will be returned, the JSON content of the document at that point may not: Cloudant cleans up the content of old tree nodes to conserve space.
The winner node🔗
The winner abstraction is key to Cloudant’s database semantics. It’s used to give the appearance of a single value for a document rather than a tree. It does this by freeing us from having to specify the rev ID of the node we want with every call – though some calls, like updates, always need one. Let’s look at how this works.
Cloudant applies the winner label to the node at the tip of the tree as shown in the diagram above. This node is the one that Cloudant will refer to when responding to document retrieval requests that do not have any particular rev ID specified. The rev ID for this node is included in the response.
While the node that Cloudant chooses to label the winner for any given document is an implementation detail, it’s essentially decided by choosing the longest path in the document tree that’s not terminated by a deletion node. This will be more obvious later when we introduce a branch to the tree.
An essential property is that Cloudant chooses which node to label winner in a deterministic way. This means that when the database is replicated, Cloudant will label the same node as winner at all replicas, given the same document tree.
Consider the last call above:
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc?revs=true'
By not specifying a rev ID to return, we’re instructing Cloudant to return information about the tree node pointed to by the winner label.
Updates are tree manipulation🔗
We’ve now seen that an update to a document can be viewed as adding a new node to the document’s tree. And we have seen that the update request’s rev parameter is specifying which existing node in the document tree should be used as the parent for this new node.
If we update twice more, we can see the tree grow. In the background, Cloudant will be updating the winner pointer to a new rev ID each time. It sends that back in the rev field of the response:
> curl -XPUT \
'http://localhost:5984/tree-demo/mydoc?rev=2-cfcd6781f13994bde69a1c3320bfdadb' \
-d '{"foo":"bop"}'
{"ok":true,"id":"mydoc","rev":"3-2766344359f70192d3a68bf205c37743"}
> curl -XPUT \
'http://localhost:5984/tree-demo/mydoc?rev=3-2766344359f70192d3a68bf205c37743' \
-d '{"foo":"bloop"}'
{"ok":true,"id":"mydoc","rev":"4-a5be949eeb7296747cc271766e9a498b"}\
Retrieving the tree description again using revs=true, we can see this has changed the JSON description of the document tree history to include the new rev IDs (node labels):
> curl -XGET 'http://localhost:5984/tree-demo/mydoc?revs=true' | jq .
{
"_id": "mydoc",
"_rev": "4-a5be949eeb7296747cc271766e9a498b",
"foo": "bloop",
"_revisions": {
"start": 4,
"ids": [
"a5be949eeb7296747cc271766e9a498b",
"2766344359f70192d3a68bf205c37743",
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
]
}
}
The tree now has four nodes, as shown by the _revisions array. As we didn’t specify a rev in the request, Cloudant has again returned the node content and history for the winner node, as we’d expect. As with any direct request to retrieve a document, we could have supplied a rev parameter to receive information about a different node.
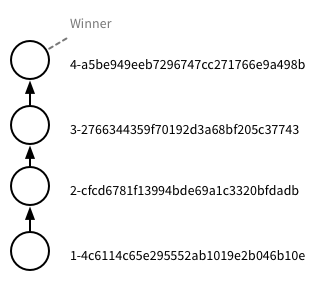
Branching in the document tree🔗
To show how the tree can branch, we need to make this document a conflicted document. A conflicted document is a document where there are two or more active branches. An active branch is one that ends in a node that is not deleted. This often happens during replication, where a document with a common history may have been updated in different ways in the databases being replicated.
If you’ve been using Cloudant for a while, you’ll be familiar with Cloudant’s behaviour when you send the “wrong” rev ID with an update: the 409 Conflict response. With our new tree knowledge, we can see that what Cloudant is doing is either (a) rejecting a request that tries to add a node to a parent which already has a child, or (b) trying to use a parent node that doesn’t exist. It does this so the tree remains a single stem, which makes sense for a database. This can be seen if we try to add a second child to our 1- revision:
$ curl -XPUT \
'http://localhost:5984/tree-demo/mydoc?rev=1-4c6114c65e295552ab1019e2b046b10e' \
-d '{"foo":"baz"}' -v
[...]
> PUT /tree-demo/mydoc?rev=1-4c6114c65e295552ab1019e2b046b10e HTTP/1.1
[...]
< HTTP/1.1 409 Conflict
[...]
{"error":"conflict","reason":"Document update conflict."}
However, we can use the _bulk_docs call to bypass these protections (which is what Cloudant’s replicator does). Clearly, this is something you’d never use day-to-day, but it’s instructive to see the effects. In the following call, we show this bypassing in action by creating a new branch rooted at the first update we made above.
The _bulk_docs request takes a JSON body describing the updates to make. First, we create the body of the request in bulk.json:
{
"docs": [
{
"_id": "mydoc",
"_rev": "3-917fa2381192822767f010b95b45325b",
"_revisions": {
"ids": [
"917fa2381192822767f010b95b45325b",
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
],
"start": 3
},
"bar": "baz"
}
],
"new_edits": false
}
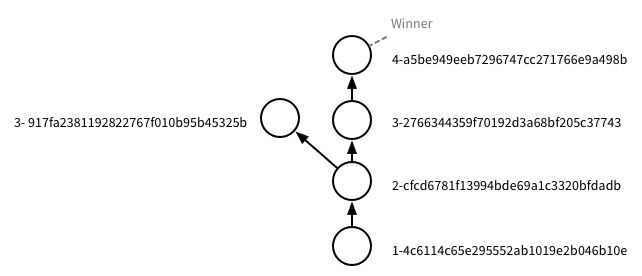
This document describes a new node for the document mydoc that we created above, 3-917fa2381192822767f010b95b45325b. This node has a history that diverges from the existing document. The new node’s history is described using the _revisions field, using the same format as we received in revs=true calls above. In this history, the first two rev IDs are the same, but the third is different. This will cause a branch to happen at rev 2-.
By including new_edits=false in the JSON, we tell Cloudant to graft this node into the document tree, creating any parent nodes required. Without new_edits=false, Cloudant would reject this update as the history is incompatible with the winner node.
Next, send the request using this body:
> curl -XPOST \
'http://localhost:5984/tree-demo/_bulk_docs' \
-d @bulk.json \
-H "Content-Type:application/json"
We now have a tree which branches. To check this, we can make a request to Cloudant that will return the content of the nodes at the tip of each branch, along with the history of each of these nodes.
The open_revs parameter is specifically used for retrieving the content of multiple tip nodes at once. To return all the branches’ tip nodes, we pass open_revs=all into the GET for the document. This is a second way to get non-winner nodes, along with specifying rev.
As above, we also include revs=true so that the history of each tip node is also returned. We also specify Accept: application/json to get a simpler return format: all the tip nodes in a JSON array.
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc?open_revs=all&revs=true' \
-H "Accept:application/json" | jq .
[
{
"ok": {
"_id": "mydoc",
"_rev": "4-a5be949eeb7296747cc271766e9a498b",
"foo": "bloop",
"_revisions": {
"start": 4,
"ids": [
"a5be949eeb7296747cc271766e9a498b",
"2766344359f70192d3a68bf205c37743",
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
]
}
}
},
{
"ok": {
"_id": "mydoc",
"_rev": "3-917fa2381192822767f010b95b45325b",
"bar": "baz",
"_revisions": {
"start": 3,
"ids": [
"917fa2381192822767f010b95b45325b",
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
]
}
}
}
]
Which represents the following tree:
Resolving the conflicted state🔗
A document is conflicted so long as it has two or more branches which don’t end in a deletion node. A conflicted document is clearly in a bad state for a database: some data is effectively hidden. So before we finish, let’s resolve the conflict. In tree terms, resolving means updating the document’s tree so that there is only one active branch.
As we have two active branches, we need to update one branch with a deletion node, called a tombstone, to make that branch inactive. We do this by making a DELETE request to the document’s resource. This request specifies the parent rev ID (rev) as the node at the tip of the branch we wish to mark as a dead end.
Before this, we need to choose which branch to keep. To do this, we need to retrieve both. Instead of using open_revs=all, we can retrieve each individually.
First, let’s look at what Cloudant considers the winner document node. This corresponds to the data it returns when a simple document lookup is carried out:
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc' | jq .
{
"_id": "mydoc",
"_rev": "4-a5be949eeb7296747cc271766e9a498b",
"foo": "bloop"
}
And, as stated earlier, we can get the other branch’s data by specifying the rev ID of the node at the tip of the other branch:
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc?rev=3-917fa2381192822767f010b95b45325b' | jq .
{
"_id": "mydoc",
"_rev": "3-917fa2381192822767f010b95b45325b",
"bar": "baz"
}
Let’s say that the non-winning node, 3-917fa2381192822767f010b95b45325b contains the JSON data we actually want for this document. We issue a delete request specifying the unwanted branch’s tip node’s rev ID as its parent:
> curl -XDELETE \
'http://localhost:5984/tree-demo/mydoc?rev=4-a5be949eeb7296747cc271766e9a498b'
{"ok":true,"id":"mydoc","rev":"5-ab21cb5ac4c8da916c47c45330d8a655"}
Recapping what we’re doing here, this request instructs Cloudant to add a tombstone node to the parent node specified by the rev parameter, thereby rendering that branch inactive.
Recall the algorithm to select the node the winner label points to is to choose the longest active path in a document tree. Therefore, after this operation, Cloudant will have moved the winner label to point at the tip of the remaining active branch. A lookup of the doc ID without specifying a rev ID therefore now returns the other node:
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc' | jq .
{
"_id": "mydoc",
"_rev": "3-917fa2381192822767f010b95b45325b",
"bar": "baz"
}
A corollary of this is that a document is not considered deleted – that is, a query for that document will not return a 404 Not Found – until all branches are inactive. This can be the source of great confusion if one doesn’t know beforehand that a document is conflicted. Deleting the document appears to bring back to life another version of the document!
If a document has many active branches, it will take several requests to add a tombstone to every branch tip to make the document actually appear deleted. Using the open_revs=all argument will show how many active branch tips there are.
Returning to our example, we can study the resulting tree using the request that we’ve made a few times now:
> curl -XGET \
'http://localhost:5984/tree-demo/mydoc?open_revs=all&revs=true' \
-H "Accept:application/json" | jq .
[
{
"ok": {
"_id": "mydoc",
"_rev": "5-ab21cb5ac4c8da916c47c45330d8a655",
"_deleted": true,
"_revisions": {
"start": 5,
"ids": [
"ab21cb5ac4c8da916c47c45330d8a655",
"a5be949eeb7296747cc271766e9a498b",
"2766344359f70192d3a68bf205c37743",
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
]
}
}
},
{
"ok": {
"_id": "mydoc",
"_rev": "3-917fa2381192822767f010b95b45325b",
"bar": "baz",
"_revisions": {
"start": 3,
"ids": [
"917fa2381192822767f010b95b45325b",
"cfcd6781f13994bde69a1c3320bfdadb",
"4c6114c65e295552ab1019e2b046b10e"
]
}
}
}
]
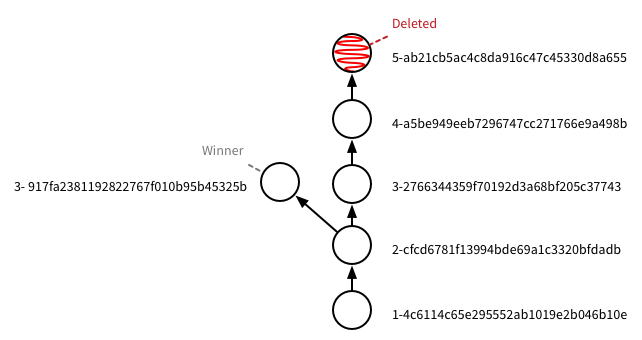
The response still shows both branches. This is expected, as the branches still exist! However, we can see that the branch ending in 5- is deleted and so the 3- branch is the only active branch. Which therefore gives us this final tree:
Conclusion🔗
Hopefully, this has shown how the Cloudant API for documents is really a tree manipulation API. There convenience wrappers and behaviours for common operations which make the API more database-like, most of which make use of the tree node labelled winner.
It’s useful to think this way, as it explains what effect requests are having on stored data which helps with understanding how to make Cloudant work effectively. It also helps to understand replication as the replication process is just using calls like the ones above to retrieve and duplicate document tree nodes from one database to another.
Before finishing, it’s worth repeating that the content of tree nodes that are not at the tip of a branch is discarded periodically by Cloudant – so don’t rely on it sticking around!