Understanding Read/Write
CouchDB 2.0 has clustering code contributed by Cloudant, which was inspired by Amazon’s Dynamo paper.
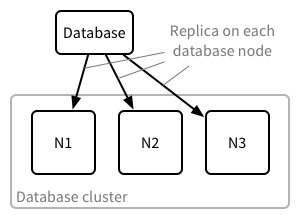
When using CouchDB in a cluster, databases are sharded and replicated. This means that a single database is split into, say, 24 shards and each shard is stored on more than one node (replica). A shard contains a specific portion of the documents in the database. A consistent hashing technique is used to allocate documents to shards. There are almost always three replicas; this provides a good balance of reliability vs. storage overhead.
Read and write behaviour differs in the clustered database because data is stored on more than one database node (server). I’m going to try to explain what the behaviour is and why it is how it is.
To simplify the explanation, I’m going to assume a database with a single shard, though still with three replicas. This just makes the diagrams simpler, it doesn’t change behaviour. In this case we have a three node cluster, so the database has a replica on every database node in the cluster.
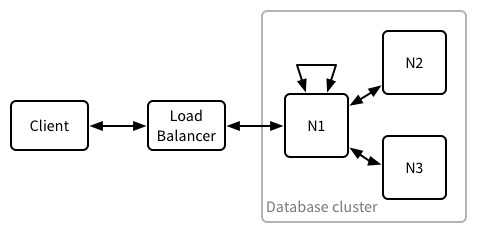
Behaviour in a healthy cluster🔗
To start with, in a healthy cluster, a read or write proceeds like this:
- Client request arrives at the cluster’s load balancer.
- The load balancer selects a node in the database cluster to forward the request to. This can be any node. The selected node is called the coordinator for this request.
- Each node maintains a shard map which tells the node where to find the shard replicas for a given database, and what documents are found in each shard. The coordinator uses its shard map to work out which nodes hold the documents for the request.
- The coordinator makes a request to each node responsible for holding the data required by the request. This might be a read request, write request, view request etc. Note: if the coordinater holds a required shard replica, one of these requests is to itself.
- The coordinator waits for a given number of responses to arrive from the nodes it contacted. The number of responses it waits for differ based on the type of request. Reads and writes wait for two responses. A view read only waits for one. Let’s call the number needed R (required responses). A few requests allow this to be customised using parameters on the request, but the defaults are almost always most appropriate.
- The coordinator processes the responses from the nodes it contacted. This can be a varying amount of work. For reads and writes, it just has to compare the responses to see if they are the same before returning a result to the client. For a view request, it might have to perform a final reduce step on the results returned from the nodes.
- Finally, the coordinator passes the response back to the load balancer which passes the response back to the client.
In this article, we’re interested in what happens when R responses are not received in step (5). CouchDB indicates this via a response’s HTTP status code for some requests. For other requests, it’s not currently possible to tell whether R responses were received.
Behaviour in a partitioned cluster🔗
The behaviour of the cluster is similar whether it’s partitioned or a node has been taken offline. A partitioned cluster just makes life easier for me because I can illustrate more scenarios with a single diagram.
Our scenario is:
- A cluster with three nodes which is split into two partitions, A and B.
- Partition A contains two nodes, and therefore two replicas of the data.
- Partition B contains one node, and therefore one replica of the data.
- For whatever reason, the load balancer from the cluster can talk to both partitions, but the nodes in each partition are isolated from each other.
- We assume the nodes know that the partition has occurred. Details on the converse state are below.
- We further assume that the nodes on each side of the partition operate correctly. In particular, that they’re able to promptly reply to the coordinators requests. The reason for this will become clear later.
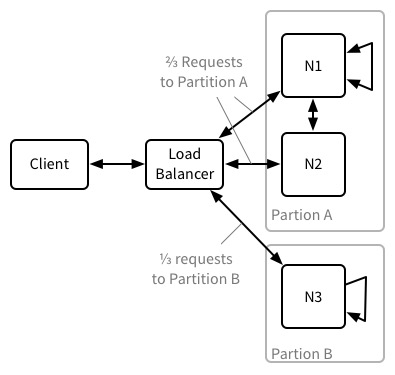
From the above description of the read and write path, it should be clear that in this scenario some reads and writes will be allocated to coordinator nodes in Partition A and some to the node in Partition B.
Reads and writes to Partition A🔗
As noted above, the default value for R is 2 for reads and writes to the database. For searches, view reads and Cloudant query requests R is implicitly 1. It should be clear that all reads and writes to Partition A will be able to receive at least R responses in all cases. In this case, the responses to the client will be as follows:
- A read or query will return
200HTTP code along with the data. - A write will return a
201 CreatedHTTP code to indicate it wrote the data toR(or more) replicas.
Reads and writes to Partition B🔗
Partition B is more interesting. It’s clear we can still meet the implicit R for searches, view reads and Cloudant Query requests. However, the nodes in Partition B cannot meet the two responses required for R for document read and write operations. So what do we do? In essence, the available node will do its best to read and write the data. Specifically, it will read from and write to its own replica of the data. Its returned HTTP status codes and body data are:
- A read will still return
200along with the latest version of the document or view/search/query data the node has (read from the single replica). Currently there is no way to tell that fewer thanRreplies were received from nodes holding replicas of shards. - A write will return a
202 Acceptedto indicate that the coordinator received a reply from at least one replica (i.e., the one in Partition B, itself) but fewer thanRreplies.
A note on responses🔗
In the above, it’s easy to overlook the fact that R is all about replies to the coordinator’s requests. For writes in particular, this has some ramifications that it’s important to take note of.
- A
202could be received in a non-partitioned cluster. For some reason a replica might receive the write request from the coordinator node, write the data but for some reason not respond in a timely manner. Responses to a client therefore guarantee only a lower-bound to the number of writes which occurred. While there may have beenR(or more) successful writes, the coordinator can only know about those for which it received a response. And so it must must return202. - Interestingly, this also means writes may happen where the coordinator receives no responses. The client receives a
500response with areason: timeoutJSON body, but the cluster has still written the data. Or perhaps it didn’t – neither the coordinator nor therefore the client can know. - For reads, the behaviour differs slightly when the coordinator knows that it cannot possibly receive
Rresponses. In that case, it returns when it has received as many as it is able to – in Partition A this is two, in Partition B this is one. If, instead, nodes are just slow to respond, if the coordinator doesn’t receive R responses before its timeout, it will return a500. See this mailing list thread.
This all illustrates that it’s essential to remember that R is all about responses received by the coordinator, and not about, for example, whether data was written or not to a given number replica. This is why it was called out in the description of the partitioned cluster that nodes reply promptly.
Concurrent modifications🔗
As time goes by, it’s clear from the above that CouchDB 2.0 will accept writes to the same document on both sides of the partition. This will mean the data on each side of the partition will diverge.
For writes to different documents, all will be well. When the partition heals, nodes will work out amongst themselves which updates they are missing and update themselves accordingly. Soon all nodes in the cluster will be consistent with each other, and fully up-to-date.
For changes made to the same document on both sides of the partition, the nodes will reconcile divergent copies of a document to create a conflicted document, in exactly the same manner as happens when remote CouchDB instances replicate with each other. Again, all nodes will become consistent; it’s just some documents are conflicted in that consistent state. It is the user’s responsibility to detect and fix these conflicts.
There is a brief discussion of resolving conflicted documents in the CouchDB docs. In essence, the cluster will continue to operate, returning one of the versions of the document that was written during the partition. The user must provide the logic for merging the changes made separately during the partition.
Conclusion🔗
This short discussion shows that CouchDB 2.0’s clustering behaviour favours availability of data for both reading and writing. It also describes the coordinating node’s behaviour in the face of partitions and how it indicates this to the client application, in particular how and why it is related purely to the number of responses received during operations.
It’s important to understand this, and what happens as data diverges on the different sides of a network partition – and how to fix the results of this divergence – in order to create well-behaved applications. However, this behaviour does allow the building of extremely robust programs with the careful application of knowledge and conflict handling code.