Automated Daily Backups
Cloudant is already reslient in that it stores data in triplicate across a region’s three availability zones but that’s not the same thing as having a backup:
- what if you delete or modify a bunch of documents and wish to restore them later? (Note that you can access the previous revision of a document for a short time, but it will be eventually compacted so this behaviour isn’t to be relied upon).
- what if you accidentally delete a whole database in error and need to restore it? (Note that Cloudant on Transaction Engine has an undelete function that allows deleted databases to be restored within a time window)
- it’s good practice to have another copy of your data elsewhere in the event of a disaster.

Photo by Ashim D’Silva on Unsplash
In this article we’ll create a serverless backup utility which can be triggered to run periodically to backup a Cloudant database to IBM Cloud Object Storage:
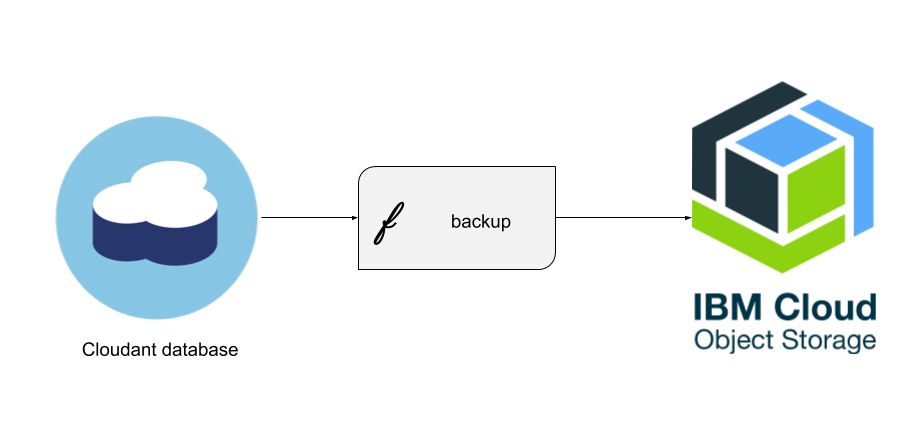
To follow this tutorial you’ll need:
- an IBM Cloud account.
- an IBM Cloudant service containing a database to backup.
- an IBM Cloud Object Storage service with a new empty bucket inside.
- the IBM Cloud command line interface with the IBM Cloud Functions CLI plugin.
Couchbackup🔗
The couchbackup utility is a command-line tool that allows a Cloudant database to be turned a text file.
# turn our "animals" database into a text file
couchbackup --db animals > animals.txt
It comes with a matching utility which does the reverse: restores a text file back to a Cloudant database.
# restore our animals backup to a new database
cat animals.txt | couchrestore --db animals2
All we need to do is trigger couchbackup periodically to perform a backup. To do this we’ll use IBM Cloud Functions, which allows code to run serverlessly, meaning you pay only for the execution time and nothing while your application stands idle.
Creating a suitable Docker image🔗
To create a Docker image suitable for running inside the IBM Cloud Functions platform we need a file called Dockerfile containing the definition of our image:
# based on the IBM Cloud Functions Node.js runtime
FROM ibmfunctions/action-nodejs-v10
# with additional npm modules for Cloudant & COS
RUN npm install ibm-cos-sdk@1.6.1
RUN npm install @cloudant/couchbackup
The image is based on the existing IBM Cloud Functions Node.js runtime but adds two additional Node.js modules:
- ibm-cos-sdk - to allow us to write data to IBM Cloud Object Storage.
- @cloudant/couchbackup - to perform the Cloudant backup operation
Assuming you have a DockerHub account (let’s assume a username of x), you can build the image with the following terminal commands:
docker build -t x/cloudant_backup .
docker push x/cloudant_backup:latest
If you don’t want to build the Docker image yourself, there is one already built using this definition at https://hub.docker.com/repository/docker/choirless/backup which we’ll use in the rest of the tutorial.
Making a backup script🔗
The Docker image provides the operating system, the IBM Cloud Functions scaffolding and the libraries we need - all that is required is to add our own custom code to allow us to backup a Cloudant database to Object Storage programmatically. Here’s an example:
const couchbackup = require('@cloudant/couchbackup')
const AWS = require('ibm-cos-sdk')
const stream = require('stream')
const main = async function (args) {
// combine bare URL with source database
if (!args.CLOUDANT_URL || !args.CLOUDANT_DB) {
return Promise.reject(new Error('missing Cloudant config'))
}
const fullURL = args.CLOUDANT_URL + '/' + args.CLOUDANT_DB
// COS config
if (!args.COS_ENDPOINT || !args.COS_API_KEY || !args.COS_SERVICE_INSTANCE_ID || !args.COS_BUCKET) {
return Promise.reject(new Error('missing COS config'))
}
const COSConfig = {
endpoint: args.COS_ENDPOINT,
apiKeyId: args.COS_API_KEY,
ibmAuthEndpoint: 'https://iam.ng.bluemix.net/oidc/token',
serviceInstanceId: args.COS_SERVICE_INSTANCE_ID
}
const cos = new AWS.S3(COSConfig)
const streamToUpload = new stream.PassThrough({ highWaterMark: 67108864 })
const key = `${args.CLOUDANT_DB}_${new Date().toISOString()}_backup.txt`
const bucket = args.COS_BUCKET
const uploadParams = {
Bucket: args.COS_BUCKET,
Key: key,
Body: streamToUpload
}
console.log(`Backing up DB ${fullURL} to ${bucket}/${key}`)
// return a Promise as this may take some time
return new Promise((resolve, reject) => {
// create a COS upload operation hanging on a stream of data
cos.upload(uploadParams, function (err, data) {
if (err) {
return reject(new Error('could not write to COS'))
}
console.log('COS upload done')
resolve(data)
})
// then kick off a backup writing to that stream
couchbackup.backup(fullURL, streamToUpload, { iamApiKey: args.CLOUDANT_IAM_KEY },
function (err, data) {
if (err) {
return reject(err)
}
console.log('couchbackup done')
}
)
})
}
module.exports = {
main
}
Most of the above code involves the the handling of the incoming parameters which are listed here:
CLOUDANT_IAM_KEYe.g. ‘abc123’CLOUDANT_URLe.g ‘https://myservice.cloudantnosqldb.appdomain.cloud’CLOUDANT_DB: e.g. ‘mydata’COS_API_KEYe.g. ‘xyz456’COS_ENDPOINTe.g ‘s3.private.eu-gb.cloud-object-storage.appdomain.cloud’,COS_SERVICE_INSTANCE_IDe.g. ‘crn:v:w:x:y:z::’COS_BUCKETe.g. ‘mybucket’
The values you’ll need can be found in your Cloudant and Cloud Object Storage service credentials, apart from COS_ENDPOINT which can be found here. Note that if the IBM Cloud Functions region and IBM Cloud Object Storage region are the same, then a “private” endpoint can be chosen to keep the traffic within the data centre.
If our code is written to an index.js file, we can deploy to IBM Cloud Functions with:
# create a new Cloud Functions package
ibmcloud fn package create cron
# create a function in the cron package based on the Docker image
ibmcloud fn action update cron/backup --docker choirless/backup:latest index.js
We now have an IBM Cloud Function called cron/backup which is based on our Docker image and adds our index.js script.
Executing a backup🔗
To avoid having to pass all of the configuration options in with each execution, we’re going to bind most of the configuration (all items except the database name) to the function. Create a JSON file opts.json containing your configuration:
{"CLOUDANT_IAM_KEY":"abc123","CLOUDANT_URL":"https://myservice.cloudantnosqldb.appdomain.cloud","COS_API_KEY":"xyz456","COS_ENDPOINT":"s3.private.eu-gb.cloud-object-storage.appdomain.cloud","COS_SERVICE_INSTANCE_ID":"crn:v:w:x:y:z::","COS_BUCKET":"mybucket"}
Then bind this configuration to your action:
ibmcloud fn action update cron/backup --param-file opts.json
This means that when we execute the action we only need provide the one missing parameter: the name of the database to backup:
ibmcloud fn action invoke cron/backup --result --param CLOUDANT_DB mydb
Scheduling a backup to run periodically🔗
We can tell IBM Cloud Functions to run our action once every 24 hours for each database we need to backup:
# backup each database after midnight
# mydb1 database
ibmcloud fn trigger create mydb1BackupTrigger --feed /whisk.system/alarms/alarm --param cron "5 0 * * *" --param trigger_payload "{\"CLOUDANT_DB\":\"mydb1\"}"
ibmcloud fn rule create mydb1BackupRule mydb1BackupTrigger cron/backup
# mydb2 database
ibmcloud fn trigger create mydb2BackupTrigger --feed /whisk.system/alarms/alarm --param cron "10 0 * * *" --param trigger_payload "{\"CLOUDANT_DB\":\"mydb2\"}"
ibmcloud fn rule create mydb2BackupRule mydb2BackupTrigger cron/backup
Scheduling an invocation of an IBM Cloud Function is a two-part process:
- create a trigger which fires at a known time using cron format to indicate which times to fire. The trigger includes the “payload” which will be supplied to our function during execution, containing the database name to backup.
- add a rule which associates the invocation of your function with the firing of the trigger.
In the above example mydb1 is backed up at five past midnight every day and mydb2 five minutes later.
Limitations🔗
This approach is reasonable for small Cloudant databases but IBM Cloud Functions has a ten minute execution limit so very large databases would not complete in time.
For very large databases, consider consuming a database’s changes feed, passing in a last known since value to get incremental changes.