Migrating a Cloudant Account
There are several reasons why you’d want to copy data from one Cloudant account to another:
- To copy data to a different region as you want to setup a cross-region database service (e.g. Dallas and Frankfurt).
- To move from self-hosted CouchDB service to a hosted Cloudant account.
- To migrate from a Cloudant dedicated service to a cloud-based, multi-tenant Cloudant service.
- To move from a Cloudant Standard account to Cloudant on Transaction Engine account.
In this post we’ll look at how to undertake such a move and some considerations you may want to take into account while you do so. We’ll assume that we are migrating from one Cloudant account to new empty Cloudant account in a different region.

Photo by Lesly Derksen on Unsplash
Replication primer🔗
What is replication?🔗
Cloudant replication is a one-way data copy from a source database to a target database.

The source and target can be on different Cloudant accounts which can exist in different regions across the world. The mediator of the replication job can be the source account, the target account or even a third Cloudant account. Best practice is to have the quietest Cloudant account be the mediator of the replication job - in this case the target account, as it is a new empty service should be configured to “pull” the data from the source database.
One off vs continuous🔗
Replication jobs can be a one-off operation (the default) or run continuously, spooling each change from source to target until the job is cancelled.
Replication speed🔗
Replication jobs can run at different speeds depending on the values performance-related options supplied during replication setup. You may wish to throttle the speed at which replication proceeds so as not to put too much load on a production service - it’s important that your source account isn’t swamped by reads leaving no capacity for other workloads or similarly, that the target account isn’t swamped by writes. This document provides approximate documents/sec rates for different combinations of the performance parameters in practice.
Many databases🔗
A replication job only copies one database’s data from source to target. If you need to migrate multiple databases, you’ll need a replication job per database. For many databases, it’s usually not advisable to have lots of replications running at once. The couchreplicate tool allows many databases to be copied, with a configurable maximum number of replications running at any one time.
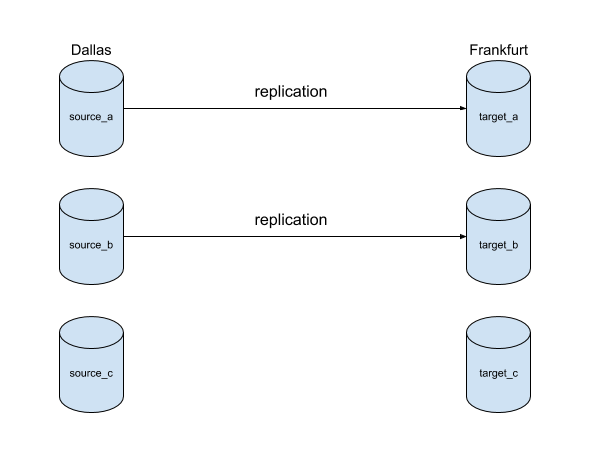
Indexing🔗
Replication only copies documents, not secondary index data. As index definitions arrive at the target (in Design Documents), the process of indexing will begin and the indexes will build asynchronously. Make sure indexes have finished building before directing production traffic to the target service.
Further reading:
Filtering documents🔗
Replicating to a new Cloudant service is a good opportunity to remove unwanted documents at the same time. Filtered replication involves supplying a Cloudant Query selector when creating a replication job - documents that meet the criteria of the selector will be replicated, everything else will be left behind.
Note that unlike Cloudant Query, a replication filter selector does not require a matching secondary index. Each changed document is passed through the selector to see if it qualifies to be replicated.
Filtered replication is useful for:
- Only replicating newer data. Supply a filter on a date field and only allow a data range through. Old data from the source can be archived to Cloud Object Storage.
- Removing deletions. Deleted Cloudant documents leave behind a “tombstone” document which can’t be deleted. A replication filter can omit these tombstones leaving the target as a pristine data set containing only non-deleted documents. A database with fewer tombstones is cheaper to host and faster to index & replicate.
Further reading:
Database sharding🔗
A Cloudant Standard database is broken into q shards, with three copies of each shard being stored around the cluster. Usually the default value of q is fine, but if you have a very large database or many very small databases, then a custom value is justified. In these circumstances creating the target database with the correct value of q is important before replicating data across.
- For most users, the default value of
qis fine. - Databases with only a few thousand documents can be created with a
qvalue of1for a boost in query performance. - Databases with more than 10GB of data per shard copy should seek the advice of the Cloudant Support team to see if a larger value of
qwould help their use-case. There are complex trade-offs to consider when operating with a larger value ofq- a good rule of thumb is to avoid an ever-growing data set if possible.
Note Cloudant on Transaction Engine automatically handles database sharding, so there’s no need to worry about
q.
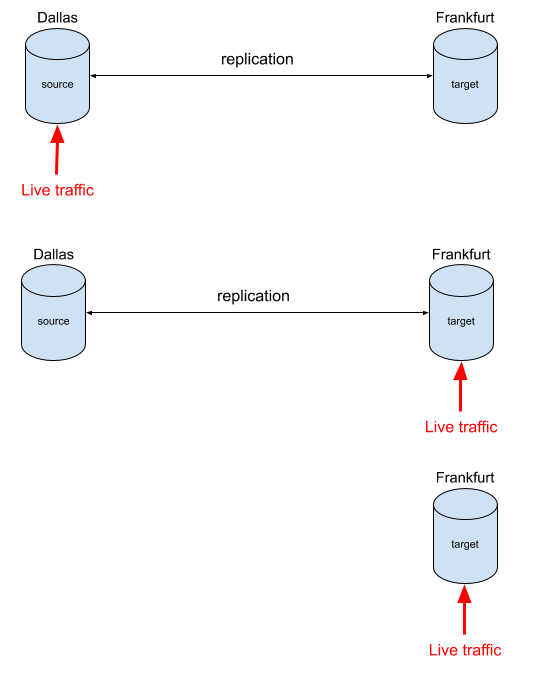
Live switchover🔗
Careful use of replication can allow an application to move from one geography to another without downtime. Continuous replication is set up to copy data from the source to the target forever.
This allows application traffic to be directed to the source, the target or to both. When you’re happy that the target is performing correctly, the replication can be deleted and the source service deleted.
If you want to hedge your bets and allow for the possibility of switching back to the source then two replications can be setup to transfer data from source–>target and target–>source. If the switchover to the new target service doesn’t work out, the source database will still be there and also be updated with any changes that were written to the target side.
Advanced filtering🔗
If your application relies on Cloudant deletions, and you also want to purge unwanted historical deletions during replication, how do you purge only the historical replications and keep any deletions that occur during the migration process as your application continues to delete documents? In short, this is the procedure to follow:
- Hit the source database’s top-level endpoint e.g.
GET /<dbname>and make a note of theupdate_seqfield. - Setup a one-off filtered replication that omits all deleted documents. Wait until replication completes.
- Setup a continuous replication (without a filter) but with a value of
since_seqequal to the sequence token fetched in Step 1. This will perform a top-up replication, taking any changes since we began the first replication including any deletions that occurred. - When you’re ready to move traffic to the new service, delete the replication from Step 3. The target database will only contain only non-deleted documents and any documents deleted since the migration process began.
Let’s take a worked example of migrating a database from https://a.cloudant.com/source to https://b.cloudant.com/target.
1. Collect a sequence token🔗
Hit the source database’s top-level endpoint and make a note of the update_seq field:
$ curl https://a.cloudant.com/source
{
"update_seq": "23579-g1AAAARXeJzLYWBgEMhgTmHQSklKzi9KdUhJMjTQS8rVTU7WLS3WLc4vLcnQNTTUS87JL01JzCvRy0styQHqYcpjAZIMH4DUfyDISmJgYH0GMkcTbo4x8cY8gBjzHmzMMVRjzIg35gLEmPtgYxajGmNOvDEHIMacBxvzkPzA2QAxZz_YnH1kB84CiDHrwcb0kx04EyDGzAcbs4rswGmAGNMPNmYPOYGTVAAkk-phqeYRGQGTlAAyIh9mxGsyAiUpAGREPMyIU2QESJIDyAh_mBFJZAWGAcgMe6gZbEzkBIYCyAh9mBEM5ASGAMgIeZhPZpARGIkMSfww_UuzAAHjZeo",
"db_name": "source",
"purge_seq": 0,
"sizes": {
"file": 11910996,
"external": 2683923,
"active": 6401972
},
"props": {},
"doc_del_count": 9,
"doc_count": 23522,
"disk_format_version": 8,
"compact_running": false,
"cluster": {
"q": 16,
"n": 3,
"w": 2,
"r": 2
},
"instance_start_time": "0"
}
Make a note of the update_seq value e.g. 23579-g1AAA....
2. Set up a one-off replication🔗
Setup a one-off filtered replication that omits all deleted documents. Wait until replication completes.
In a file, we have our replication definition:
{
"_id": "atob_oneoff_filtered",
"source": "https://a.cloudant.com/source",
"target": "https://b.cloudant.com/target",
"create_target": true,
"selector": {
"_deleted": {
"$exists": false
}
}
}
which we post to the _replicator database:
curl -X POST -H'Content-type: application/json' -d@replication.json https://b.cloudant.com/_replicator
then fetch the replication document to see its progress:
curl https://b.cloudant.com/_replicator/atob_oneoff_filtered
{
"_id": "atob_oneoff_filtered",
"_rev": "2-5b71cc6f0447a4d072712b673a7e21b3",
"source": "https://a.cloudant.com/source",
"target": "https://b.cloudant.com/target",
"create_target": true,
"selector": {
"_deleted": {
"$exists": false
}
},
"owner": "targetuser",
"_replication_state": "triggered",
"_replication_state_time": "2020-11-25T11:22:36Z",
"_replication_id": "616db26cc57fda8bda8d623f5f86a79c+create_target"
}
Check the target database to see progress:
curl https://b.cloudant.com/target
{
"update_seq": "1588-ZIUQAboY_MAcQEgANIvT3YAJDIk8YM1p2YBAAUyYaU",
"db_name": "target",
"purge_seq": 0,
"sizes": {
"file": 2580116,
"external": 187265,
"active": 470068
},
"props": {},
"doc_del_count": 0,
"doc_count": 1588,
"disk_format_version": 8,
"compact_running": false,
"cluster": {
"q": 16,
"n": 3,
"w": 2,
"r": 2
},
"instance_start_time": "0"
}
Eventually the replication will finish, when the replicator document shows a _replication_state of completed:
{
"_id": "atob_oneoff_filtered",
"_rev": "3-7e8e129401fc5d2be720b645fbd4b4c7",
"source": "https://a.cloudant.com/source",
"target": "https://b.cloudant.com/target",
"create_target": true,
"selector": {
"_deleted": {
"$exists": false
}
},
"owner": "targetuser",
"_replication_state": "completed",
"_replication_state_time": "2020-11-25T11:42:38Z",
"_replication_id": "616db26cc57fda8bda8d623f5f86a79c+create_target",
"_replication_stats": {
"revisions_checked": 23522,
"missing_revisions_found": 23522,
"docs_read": 23522,
"docs_written": 23522,
"changes_pending": 0,
"doc_write_failures": 0,
"checkpointed_source_seq": "23531-7MQYilCGitmd1fAx-HgQ",
"start_time": "2020-11-25T11:22:36Z"
}
}
3. Perform a catchup replication🔗
Next we want a set off a continuous replication to catch up changes since the sequence token we collected in step 1. Our new replication document looks like this:
{
"_id": "atob_continuous_catchup",
"source": "https://a.cloudant.com/source",
"target": "https://b.cloudant.com/target",
"since_seq": "23579-g1AAAARXeJzLYWBgEMhgTmHQSklKzi9KdUhJMjTQS8rVTU7WLS3WLc4vLcnQNTTUS87JL01JzCvRy0styQHqYcpjAZIMH4DUfyDISmJgYH0GMkcTbo4x8cY8gBjzHmzMMVRjzIg35gLEmPtgYxajGmNOvDEHIMacBxvzkPzA2QAxZz_YnH1kB84CiDHrwcb0kx04EyDGzAcbs4rswGmAGNMPNmYPOYGTVAAkk-phqeYRGQGTlAAyIh9mxGsyAiUpAGREPMyIU2QESJIDyAh_mBFJZAWGAcgMe6gZbEzkBIYCyAh9mBEM5ASGAMgIeZhPZpARGIkMSfww_UuzAAHjZeo",
"continuous": true
}
Note this replication does not have a filter - we want deletions that occurred after we started the migration to be replicated.
We post this document to the _replicator database:
curl -X POST -H'Content-type: application/json' -d@replication.json https://b.cloudant.com/_replicator
This replication will run forever, or at least until we delete the replicator document.
4. Switchover🔗
When the catchup replication is up-to-date, we can direct traffic to our target service and when we’re happy, we can delete the continuous replication we set up in step 3.