Natural Language Classification
In this post we’ll combine the Cloudant database with IBM’s Watson Natural Language Classifier (NLC) service to automatically determine whether reviews left on a website are positive or negative.
Imagine we are capturing product reviews on an e-commerce website and storing them as JSON in a Cloudant database:
{
"_id": "product885252:review1005252",
"date": "2019-01-26T15:22:41.000Z",
"product_id": "885252",
"product_name": "Gourmexia Smoothie Blender B662X",
"reviewer": "susan1982",
"review": "Very well made device. Works straight out of the box - really happy!"
}
After while, our database will hold plenty of reviews that our users can look through to help their buying decision. In order to be able to display the reviews on the website in two columns - positive and negative - we are going to need to classify whether a review is positive or negative and store that “summary” in the review JSON e.g.
{
"_id": "product885252:review1005252",
"date": "2019-01-26T15:22:41.000Z",
"product_id": "885252",
"product_name": "Gourmexia Smoothie Blender B662X",
"reviewer": "susan1982",
"review": "Very well made device. Works straight out of the box - really happy!",
"summary": "positive"
}
We will need to either capture this new “summary” data from the user when they add to the review, or we could infer whether the review is positive or negative by using Artificial Intelligence. By training a Natural Language Processing (NLP) model with some reference reviews, it should be able to classify reviews it hasn’t seen.
Not having any experience of NLP, it’s best to reach for a cloud service such as the Watson Natural Language Classifier (NLC) service.

Image by Patrick Tomasso on Unsplash
Sign up🔗
Simply add a new NLC service in your IBM Cloud dashboard by searching for “natural language”:
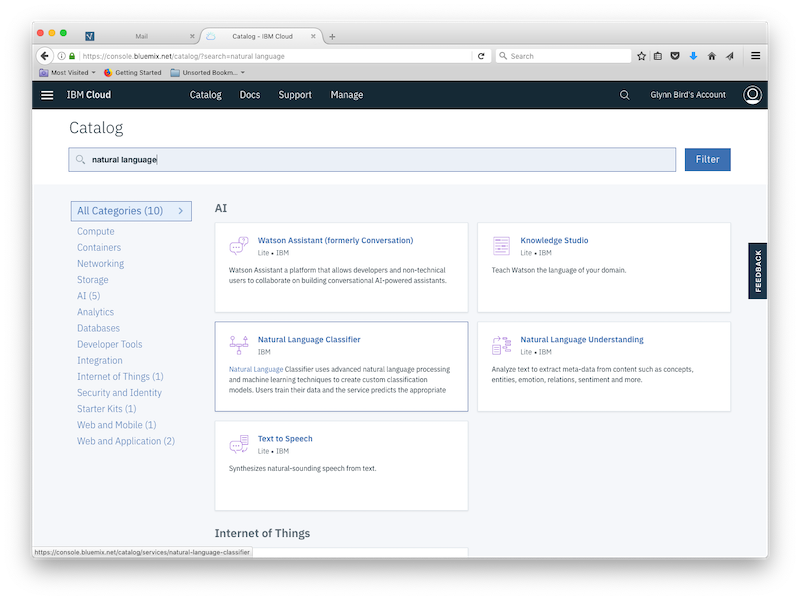
Choose a service name and pick the geography in which the service will run:
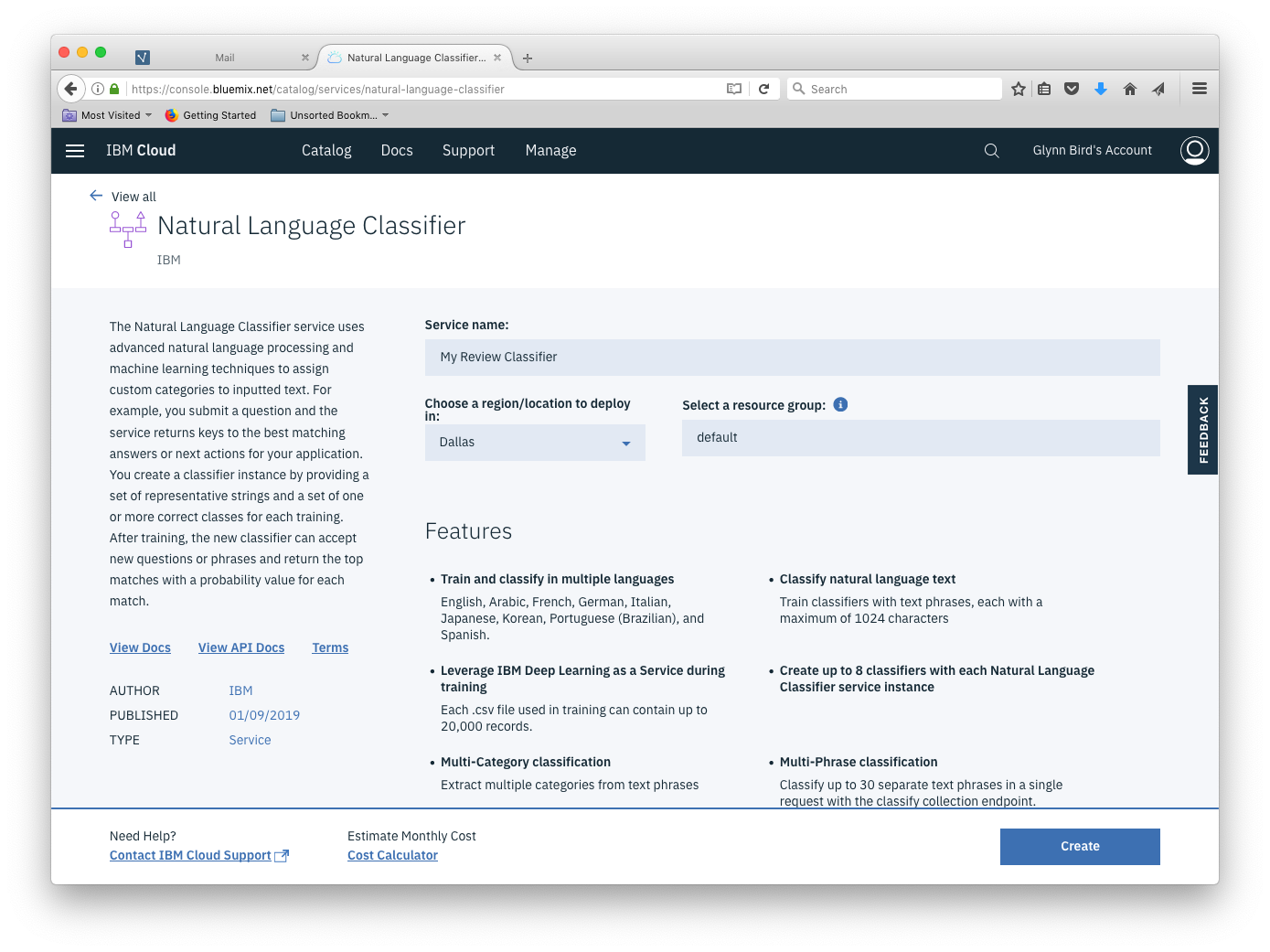
Make a note of the URL and the API Key that is delivered with your provisioned service - we’ll need them later.
Next up, we need to train our model.
Training data🔗
To train the service we need to feed it a CSV file containing examples of what a positive and negative review looks like. The CSV file contains two columns: the first with the review text and the second with the classification (positive/negative:
terrible product. Rubbish,negative
The best thing I've ever bought! Recommended!, positive
I was really pleased with this device. Would buy again,positive
Total waste of time. Returned for a refund,negative
Luckily we have a body of existing review text we can extract from our Cloudant database. I used the couchimport command-line tool that allows us to export Cloudant data as a CSV file:
couchexport --db reviews --delimiter "," > reviews.csv
We can then load this data into a spreadsheet, trim off the columns so that we only have the review text and a column for positive/negative.
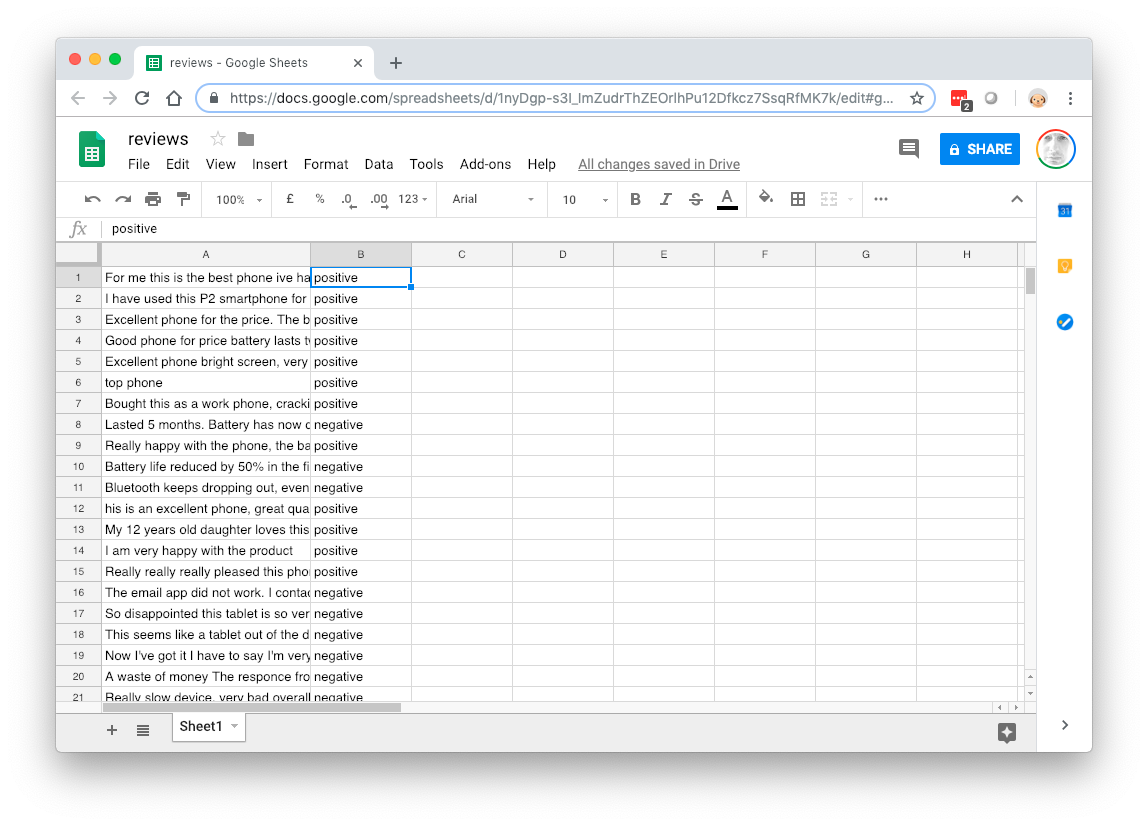
The NLC best-practice is to have fewer than sixty words of text in your training data - it would be good to remove lenghty expositions on product features from the review and leave in the parts where the user expresses an opinion on the product or service.
Then comes the laborious process of populating the second column. This is a one-off process to build the data set that will train Watson to be able to classify future reviews automatically. Once complete, export the two column spreadsheet as a CSV file and we’re ready to do the training. The NLC documentation recommends having 5-10 records of each classification in the training set.
Training🔗
The Watson NLC service is all powered by an HTTP API, so we can do all the work from the command-line using curl. To save some typing, let’s put our NLC service URL and API Key in environment variables:
export URL="https://gateway.watsonplatform.net/natural-language-classifier/api"
export APIKEY="9955882a8785grneYRRXpg5M3wBq1XwY7798gstcUm
We’re now ready to train our classifier using our reviews.csv file:
curl -i --user "apikey:$APIKEY" \
-F training_data=@reviews.csv \
-F training_metadata="{\"language\":\"en\",\"name\":\"ReviewClassifier\"}" \
"$URL/v1/classifiers"
The above command gives the classifier a name and specifies the language that the review data is written in and uploads the reviews.csv file. (If you collect reviews in different languages, you’ll need a classifier per language).
In response, the API returns you some JSON:
{
"classifier_id" : "9cccc4x485-nlc-1438",
"name" : "ReviewClassifier",
"language" : "en",
"created" : "2018-12-20T11:05:53.740Z",
"url" : "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/9cccc4x485-nlc-1438",
"status_description" : "The classifier instance is in its training phase, not yet ready to accept classify requests",
"status" : "Training"
}
This indicates the classifier_id of the model we are training and states that training is now underway. Make a note of this, as we’ll need it to query the model later. Let’s store it in an environment variable so that we don’t have to keep typing it:
export CLASSIFIERID="9cccc4x485-nlc-1438"
We can check if the model training is complete by calling another API passing in the classifier_id from the first request:
curl --user "apikey:$APIKEY" \
"$URL/v1/classifiers/$CLASSIFIERID"
After a few minutes, the response to this API call will indicate that training is complete and we’re ready to proceed to the next step.
Classifying new data🔗
Now the model is trained, we can pass it new data that it has never seen before and it will determine whether it is “positive” or “negative”:
curl -G --user "apikey:$APIKEY" \
"$API/v1/classifiers/$CLASSIFIERID/classify" \
--data-urlencode "text=The item was terrible and did not work"
{
"classifier_id" : "9cccc4x485-nlc-1438",
"url" : "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/9cccc4x485-nlc-1438",
"text" : "The item was terrible and did not work",
"top_class" : "negative",
"classes" : [ {
"class_name" : "negative",
"confidence" : 0.9608260421942736
}, {
"class_name" : "positive",
"confidence" : 0.03917395780572638
} ]
}
The resulting data will show you the
top_class- which of the classifications is the best fit.classes- a break down of the confidences that the model attributed to each class.
For our use-case we can simply take the top_class value and add it to our review JSON.
Plumbing it in🔗
All that’s left to do is to call the “classify” API endpoint upon the submission of a new product preview from the web front end and surface the “top_class” value in our stored JSON. The call can be made from anywhere, but you’ll get the smallest latencies if you provision your Watson model as geographically close as possible to your app servers.
The HTTP is pretty easy to access from any programming language. Here’s a Node.js function that classifies the passed-in string:
const request = require('request')
const classify = async (str) => {
const URL = process.env.URL
const APIKEY = process.env.APIKEY
const CLASSIFIERID = process.env.CLASSIFIERID
return new Promise((resolve, reject) => {
const r = {
method: 'get',
url: URL + '/v1/classifiers/' + CLASSIFIERID + '/classify',
qs: {
text: str
},
headers: {
Authorization: 'Basic ' + Buffer.from('apikey:' + APIKEY).toString('base64')
},
json: true
}
request(r, (e, r, b) => {
if (e) return reject(e)
resolve(b)
})
})
}
which can be called as follows to extract the “top_class” value:
const c = await classify('this product is terrible')
console.log(c.top_class)