Custom Replication
Cloudant has first-class replication built in. A database can be replicated to another local database or to a remote Cloudant instance—or to any other database that speaks the same replication protocol, such as Apache CouchDB™ or PouchDB. A replication process can be one-shot or continuous, and replication streams can be “filtered”, i.e. the documents that are replicated can be a subset of the total.
Not all applications need replication. It is essential when there are multiple, disconnected copies of the data where the data can be modified on either side. Cloudant solves the problem by never throwing away conflicting revisions of the same document and allows your app to decide how to resolve the situation.
One-way street🔗
Other apps look like they need replication but only really involve the movement of data from one place to another in one direction. This is a much simpler problem to solve and lets us get creative with replication.
Let’s take the example of a transport system. A central database contains a continuously growing collection of events:
- Bus AB12XJK has begun its journey on route X1 from Newcastle-upon-Tyne at 13:08 on 4th August 2017
- Bus AB12XJK has stopped for a break at 15:08 on 4th August 2017
- Bus AB12XJK has resumed its journey at at 15:30 on 4th August 2017
- Bus AB12XJK has arrived at its destination (Victoria Coach Station) at 19:10 on on 4th August 2017
This trip could be modelled in a Cloudant database with the following document structure:
{
"_id": "3007166d-3fd3-4e3f-be0d-43aa9c054a48", // auto-generated id
"_rev": "1-16e262673ed141f0b711f33e6bb0fdc1", // revision token
"route": "X1",
"name": "Newcastle to London Express",
"start": "Newcastle-upon-Tyne",
"end": "Victoria, London",
"scheduled_start": "2017-08-04 13:05:00 Z",
"actual_start": "2017-08-04 13:08:00 Z",
"scheduled_arrival": "2017-08-04 13:05:00 Z",
"estimated_arrival": "2017-08-04 13:08:00 Z",
"actual_arrival": null,
"stops": [
{
"type": "comfort_break",
"location": "Woodall services",
"start": "2017-08-04 15:00:00 Z",
"actual_start": null,
"end": "2017-08-04 15:30:00 Z",
"actual_end": null
}
],
"driver": {
"name": "Sheila Davies",
"employee_num": "SD_1552"
},
"vehicle": {
"model": "Volvo 9700",
"registration": "PQ89MGW"
}
}
Some things to note about this document structure:
- The document’s id is auto-generated by the database, although you could provide your own.
- The revision token contains a number (
1), a hyphen (-), and a hash of the contents of the document (16e262...). If the document changes, the number will be incremented and the system will compute a new hash. - The other fields are up to us. Our data model allows for multiple “stops” on a journey (hence the array of objects).
- This document contains everything we need to get a snapshot of the progress of this journey. Although it contains references to other data structures—route id, employee id, vehicle registration—Cloudant is not a relational database. So it is ok to take copies of related data in our object to allow us to get a useful view of the data without de-referencing everything.
We can use this data to show the progress of a particular journey on our company website, to perform analytics (e.g., statistics of how many journeys were late on arrival) and to power public displays at each end.

Image courtesy of Flickr user Carlbob.com
Moving the data🔗
Let’s imagine we were building such a display. We would need:
- A display!
- The arrivals and departures data for the station in question.
- A local data store so we can cache the data locally. If the remote database becomes disconnected, we can still render the most recent information.
We can use PouchDB or CouchDB within the display. Both are small enough to be incorporated into an embedded system, but we want to keep data volumes to a minimum. A single display only needs to know about journeys that list it as the starting or destination point. It would be overkill to replicate the entire database to each display.
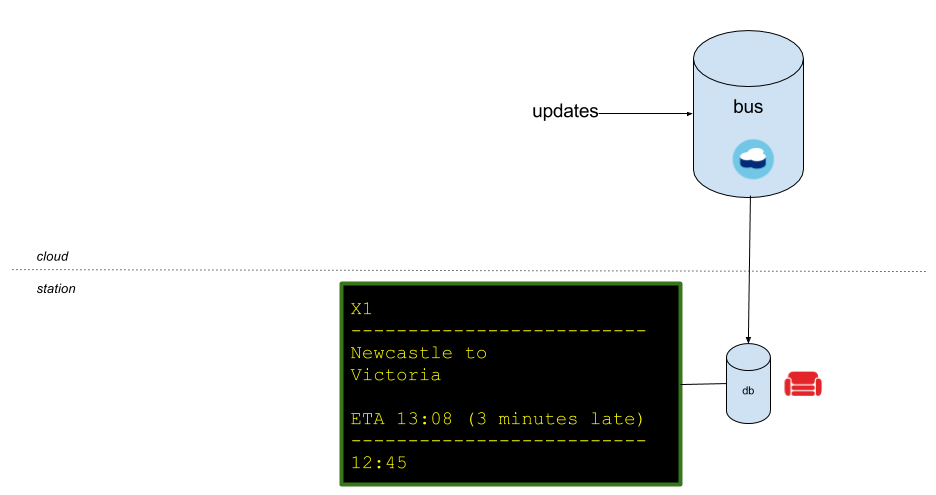
We could use Filtered Replication. This approach involves sending a JavaScript function to Cloudant—a function that decides which documents are replicated and which are not. It would be simple to create a filter by bus station (i.e., a function which passed any document whose start or destination matches the display’s station). But there are drawbacks to this approach.
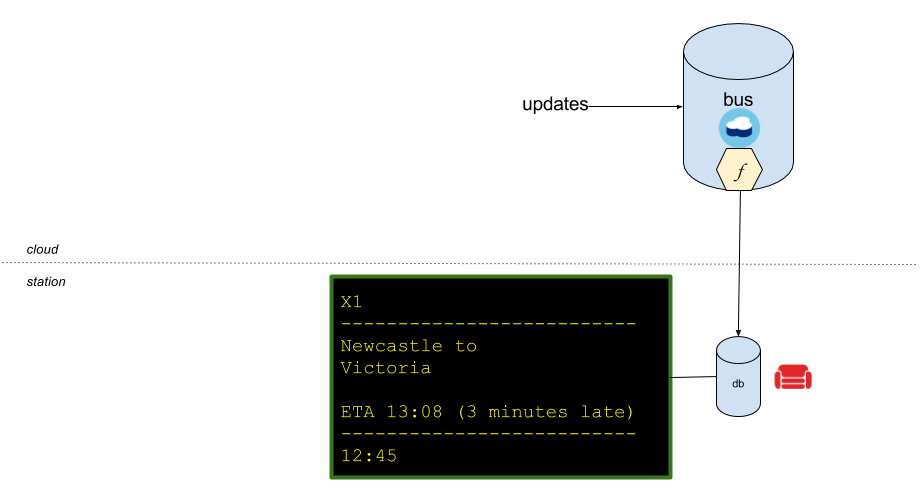
Because our database contains all documents back to the beginning of time, a first-time replication will begin at zero and have to spool through every document in turn. It would work eventually but is increasingly inefficient as the data size grows.
Another solution is to have a copy of each station’s data in its own database:
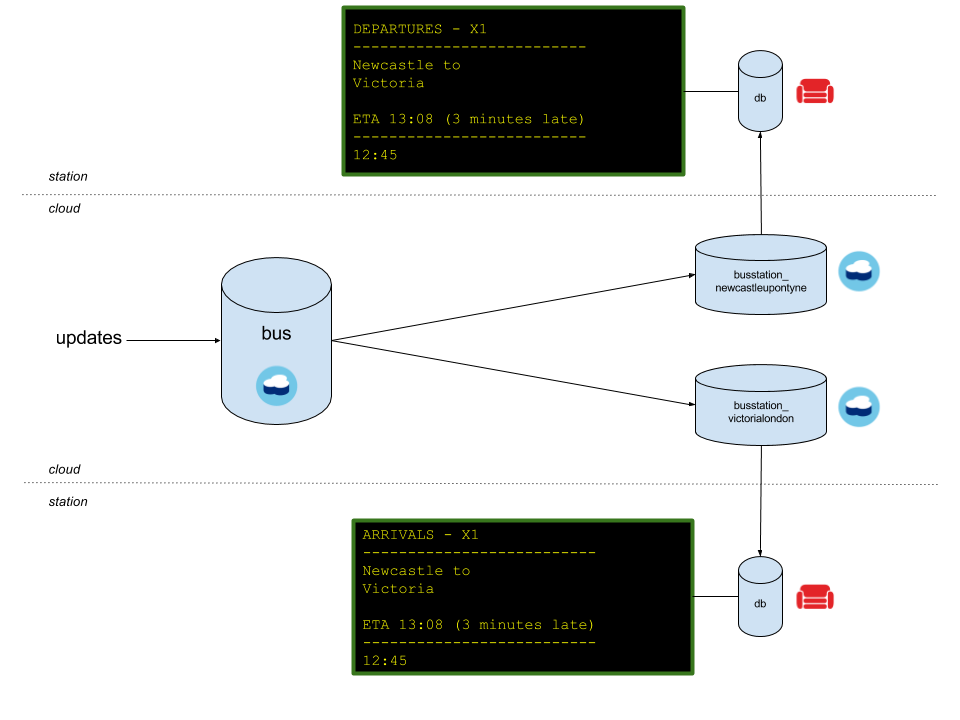
This “one database per station” approach has some advantages:
- The station display can replicate the data easily from its paired database without filtering and with a reduced data size.
- The per-station databases can be destroyed and recreated daily, keeping the replicatable data sizes much smaller because the display boards are only interested in today’s data and the data only pertains to its station.
- The per-station databases could contain only a subset of the original document—just the bare minimum required for the display boards, keeping the document sizes small.
Building a custom Cloudant replication🔗
My solution doesn’t use Cloudant replication to feed the per-station databases. Instead, it uses the OpenWhisk serverless platform. An OpenWhisk Node.js function is called with each change on the main database. The code identifies which per-station databases need to be fed (the start and destination stations and any calling points along the way), prunes the document structure, and makes the writes to the relevant “per station” databases.
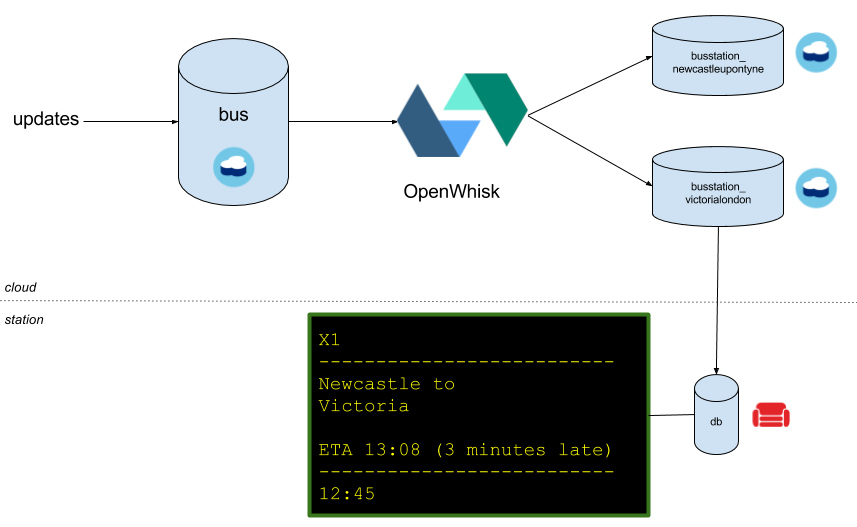
Here’s the sample code. It includes the OpenWhisk action that is called with every change and a deployment script that deploys it to OpenWhisk and creates the Cloudant changes feed trigger.
Building your own🔗
Fork the code and build your own logic to decide how data is routed from your primary database to the secondary database(s).
Hopefully this article provided some new ideas for thinking about data movement in your own applications. If you enjoyed it, the clap button awaits you below.