Count Distinct
In 2017 I blogged about creating custom indexes outside of Cloudant for problems that didn’t fit Cloudant’s indexing engine. One of those was the count distinct problem.
Imagine you are recording web events as people (and bots) interact with your website - events that look like this in JSON documents in a Cloudant database:
{
"_id": "96f898f0f6ff4a9baac4503992f31b01",
"_rev": "1-ff7b85665c4c297838963c80ecf481a3",
"path": "/blog/post-1.html",
"date": "2018-12-04",
"time": "17:15:59",
"mobile": true,
"browser": "Chrome",
"ip": "85.25.222.52"
}
We want to report on the number of distinct IP addresses that have visited our site but as there are around four billion possible IP addresses, a count distinct operation can use vast amounts of memory. At the time, I proposed using Redis’s HyperLogLog index instead - this achieves an approximate count using only a fixed handful of kilobytes of memory.

Photo by Sylvanus Urban on Unsplash
As of CouchDB 2.2, a HyperLogLog-based reducer is available to allow approximate count distinct operations to be performed in MapReduce indexes. Here’s how it’s done.
The Map function🔗
We are going to create a MapReduce index whose key is the thing we want to count (the ip address). A JavaScript function is defined as the “map” part of the MapReduce to emit the required key:
function(doc) {
emit(doc.ip)
}
This creates an index ordered by ip address - one item per document:
1.142.99.0
77.152.2.245
85.25.222.52
The reducer🔗
The new _approx_count_distinct reducer will reduce this index to approximate count of the distinct keys in the index:
{"rows":[
{"key":null,"value":50133}
]}
So across the data set there are approximately 50133 distinct ip addresses (with a relative error of 2%).
At query time, you may also examine ranges of keys. Let’s say you wanted to examine traffic from your own local 192.168.* network
#?startkey="192.168.0.0"&endkey="192.169.0.0"
{"rows":[
{"key":null,"value":99}
]}
Using the _approx_count_distinct in the dashboard🔗
The MapReduce definition can be created in the Cloudant dashboard:
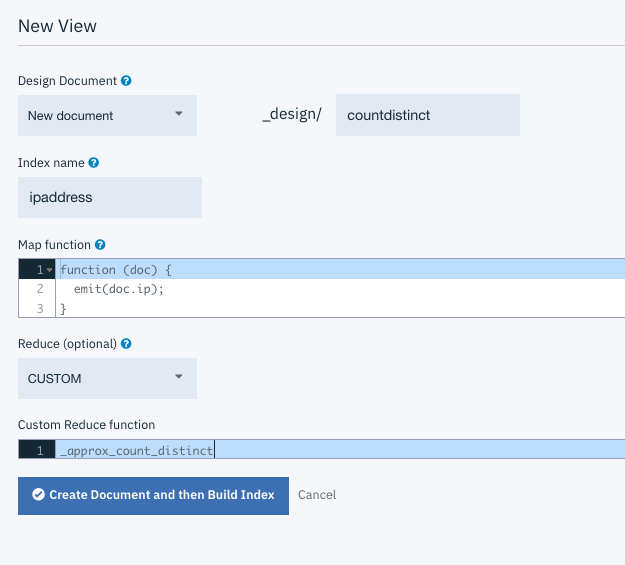
Add your map function and choose the _approx_count_distinct reducer or enter _approx_count_distinct in the CUSTOM text box.
Conclusion🔗
The _approx_count_distinct reducer has one job: to provide an estimate of distinct counts (with an accuracy of 2%) much more efficiently than getting a precise answer. It is used in the same way as the other built-in reducers _sum, _count and _stats but remember that it acts on the index’s key, not the value.