Replicating from a Query
Cloudant and CouchDB’s replication protocol allows documents to be copied from a source database to a target database with the minimum of fuss. This unlocks a wealth of use-cases:
- Multiple copies of a database across geographies to allow for disaster recovery, or to be used in a high-availability configuration.
- Data being replicated from a cloud-based primary to an on-premise backup.
- Mobile devices taking a copy of data, taking if offline and modifying it before replicating it back to the original source database.
The first two use-cases usually require the whole source database to be replicated, but the third use-case is different and is an example of what I call the roving engineer problem.

Photo by Cosmin Gurau on Unsplash
The roving engineer problem🔗
Let’s say our company installs electric vehicle charging points. We have hundreds of mobile engineers and a database of all of our company’s appointments stored in Cloudant - one document per appointment:
{
type: "appointment",
status: "booked",
address: {
street: "25 Front Street",
town: "Pleasantville",
state: "CA",
zip: "152422"
},
model: "KwikCharge 550S",
customer: "Tom Pickering",
date: "2019-06-30",
engineer: "501"
}
We want to replicate each engineer’s appointment documents to their mobile device so that they can take them with them (sometimes into remote areas without cellular coverage). During the installation, the engineers will add more fields to the document to record the serial number of the device they installed, the time they arrived & left etc. Mobile apps built with PouchDB allow Cloudant documents to reside inside a web browser (or embedded in a browser inside a Apache Cordova container). PouchDB speaks the same replication protocol as Cloudant, so moving data about is a breeze.
At the end of the day, or at any time when the engineer’s mobile is connected, they can sync back the data to the Cloudant service.
Let’s look at the ways this design pattern can be achieved.
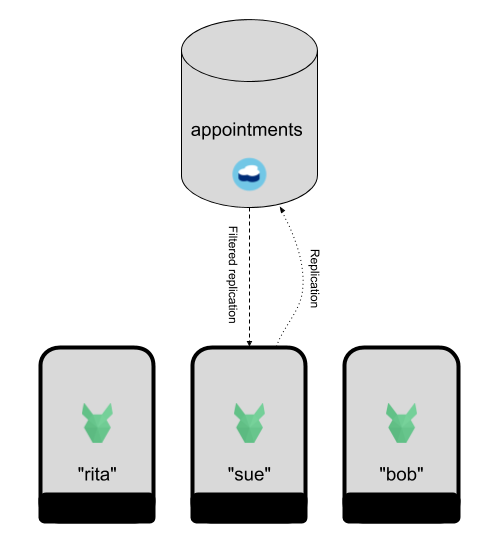
Option 1: Filtered replication🔗
A Cloudant replication between source and target databases can be filtered, that is a JavaScript function decides whether each document makes it through to the target or is rejected. This can, in theory, be used to implement the roving engineer problem. We create a filter function:
function(doc, req) {
// ensure this is an appointment that has been booked
// and is assigned to our engineer (passed in at replication-time)
if (doc.type === 'appointment' &&
doc.status === 'booked' &&
doc.engineer === req.query.engineer) {
return true
} else {
return false
}
}
We can then trigger a replication from PouchDB, specifying that we wish to filter the documents with our engineer’s id.
This would work, but it’s slow. The first replication would ask Cloudant to trawl through every document in the database to find the handful of documents that pass the filter function’s test. Subsequent replication’s could be faster, because they wouldn’t have to start from the beginning of the source database’s changes feed, but the process would still have to sift through every engineer’s documents in search of those pertaining to one engineer.
Option 2: One database per user🔗
The one database per user pattern is common in CouchDB/Cloudant circles because it allows a clean replication target/source that only contains one user’s documents.
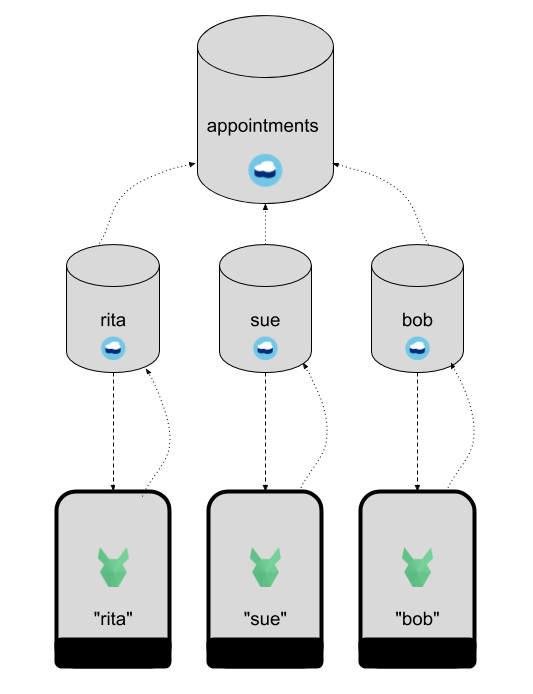
This is much better than filtering the replication from one large database but does have some drawbacks:
- The server-side databases gets bigger and bigger with each day. In this use-case only the new or recent documents are of interest to the mobile client, but replication is going to bring all the documents down to the mobile database.
- With application data split out into hundreds of separate databases, it is difficult to query the data as a whole. One solution is to replicate the small databases into a large central database which can then be used for reporting.
Option 3: Replicating from a query🔗
Ideally, we’d like to keep a single server-side database to make reporting easy but we also want to keep the data size small on the mobile side. Starting with a blank mobile-side database every day we would like to replicate only the data that is of interest to one user in restricted time-window. Effectively, we would like to copy data based on a query and push the matching records to the clean, mobile database. This isn’t a built-in feature of Cloudant but is easily achievable with a few steps:
- Perform the query to get the list of document ids to copy. In our case, it’s going to be a handful of documents. Note that the query should be backed by a suitable index to keep performance snappy.
- Fetch the document bodies including the replication history matching the document ids from step 1.
- Write the documents to the mobile-side database, retaining the replication history
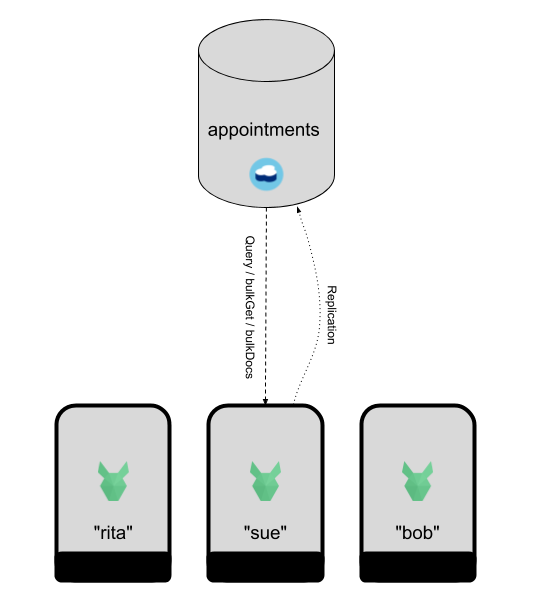
Here’s how this achieved with client-side JavaScript:
// clean out the client-side database
const DBNAME = 'apointments'
var db = new PouchDB(DBNAME)
await db.destroy()
db = new PouchDB(DBNAME)
// remote database
var cloudantDB = new PouchDB('https://user:pass@host/dbname')
// perform the query on the server-side database
// Find documents which are appointments that have been booked
// for our engineer id and that are in the future.
const q = {
selector: {
type: 'appointment',
status: 'booked',
engineer: '501',
date: {
'$gte': '2019-06-13'
}
},
fields: ['_id']
}
const data = await cloudantDB.find(q)
// swap _id for id
data.docs.map((obj) => { obj.id = obj._id; delete obj._id })
// fetch the document bodies with revision history
const bulkGetData = await cloudantDB.bulkGet({docs: data.docs, revs: true})
let docs = []
for(var i in bulkGetData.results) {
docs.push(bulkGetData.results[i].docs[0].ok)
}
// write to local PouchDB
const response = await db.bulkDocs(docs, {new_edits: false})
Much of this algorithm is formatting the output of one API call so that it’s suitable for the input of another but there’s a few import points:
bulkGetfetches a list of documents at once by their_idwhile also returning the documents’ revision histories, which is important if you are writing your own replicator.bulkDocswrites documents in bulk with thenew_edits: trueflag that specifies that no new revision tokens are to be generated - each document’s revision tree is grafted on the local database’s existing revision tree.
PouchDB replication uses bulkGet/bulkDocs in its internal implementation, the difference between our custom replicator and standard replication is that ours is triggered from a smaller subset of data - the output of the find query operation.
In our use-case, the data set being “replicated” is small (a handful of documents). If your use-case requires larger volumes of documents to be copied, then you’ll need to repeat the bulkGet/bulkDocs step, in batches of, say, a hundred documents at a time, paging through repeated query result sets.
Closing the loop🔗
Whichever option we pick to copy data to our mobile device, our engineers now have their documents in PouchDB and can take them to their remote site to do their installation work. They can modify the appointment documents to add data they collect on site, creating new revisions of the documents in PouchDB as they do so. When the engineer is ready to upload their work, a simple db.replicate.to(cloudantDB) call is all that is required to push those revisions to Cloudant.
If there’s a possibility that an server-side appointment document could have been modified while the engineer was out and about, then it’s essential to check for and repair document conflicts. When two documents are modified in different ways by disconnected replicas of a database, Cloudant doesn’t discard data on sync, it keeps the clashing versions as conflicts in its revision tree. It is your application’s responsibility to detect and tidy up conflicts.
If you want to avoid conflicts altogether, then the next section shows you how.
Avoiding conflicts during replication🔗
Conflicts can be avoided altogether by keeping data separate:
- The appointment documents, which are generated server-side when an installation job is requested contain the meta data about the job. Ensure that only the server-side process can modify these documents.
- The engineer-generated data should be stored in new, separate documents to store the data collected on site. The documents can reference the original appointment, but the original appointment document remains untouched.
{
type: "installation",
appointmend_id: "31VHCIFR4SCKFTMV",
engineer_id: "501",
arrived: "2019-06-30 10:30:00",
left: "2019-06-30 11:56:00",
model: "KwikCharge 550S",
serial: "885527727725772",
notes: "Installed to the left of garage.",
tested: true,
current: 13,
car: "Nissan Leaf"
}
By keeping the appointment data separate from the installation data, that is the data generated server-side from the data generated when on-site, we can completely avoid the possibility of conflicts and the necessity of having to detect and repair them.
Conclusion🔗
The roving engineering problem can be solved a number of ways with Cloudant, but a great solution is writing your own “Replication from a Query” algorithm so that only the documents you need are copied to a clean mobile database.